Hey, I’m Kirill, a multidisciplinary executive
design director
from Latvia and Spain, working remotely last 10 yrs.
Hey, I’m Kirill, a multidisciplinary executive
design director
from Latvia and Spain, working remotely last 10 yrs.
A Place to Be, Jun 2023... Present
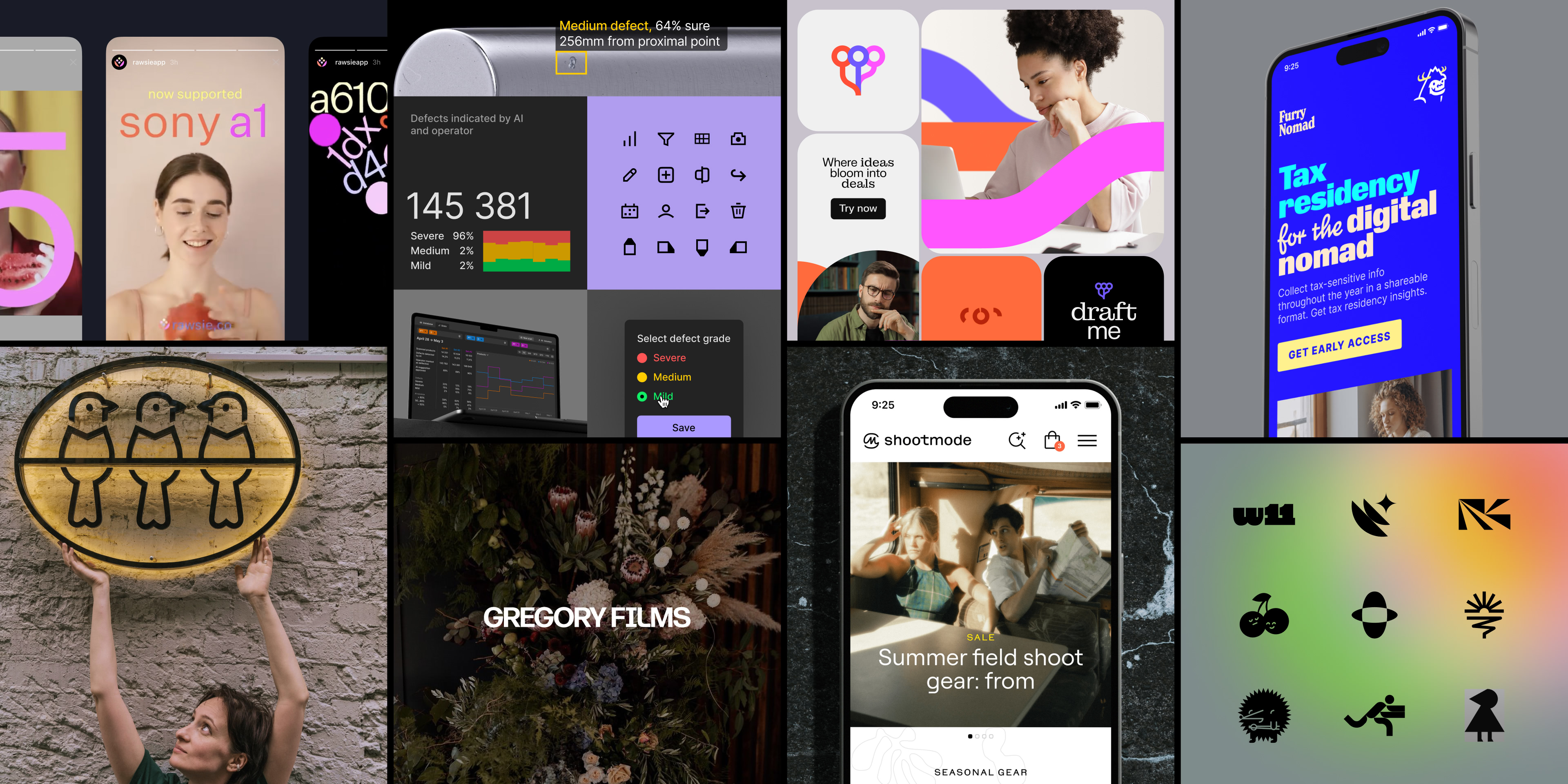
After three years of collaboration, Boris and I are launching a branding studio. We work with large companies and startups from Europe, US, and Australia. We specialise in branding digital products, establishments, and events.
In Tunnel Tech, I experienced the flavor of multidisciplinary work and collaboration. Over the past three years, I have collaborated with various startups at different stages, including Oraculum, Animopus, Pivot, Brickit, and Retenly.
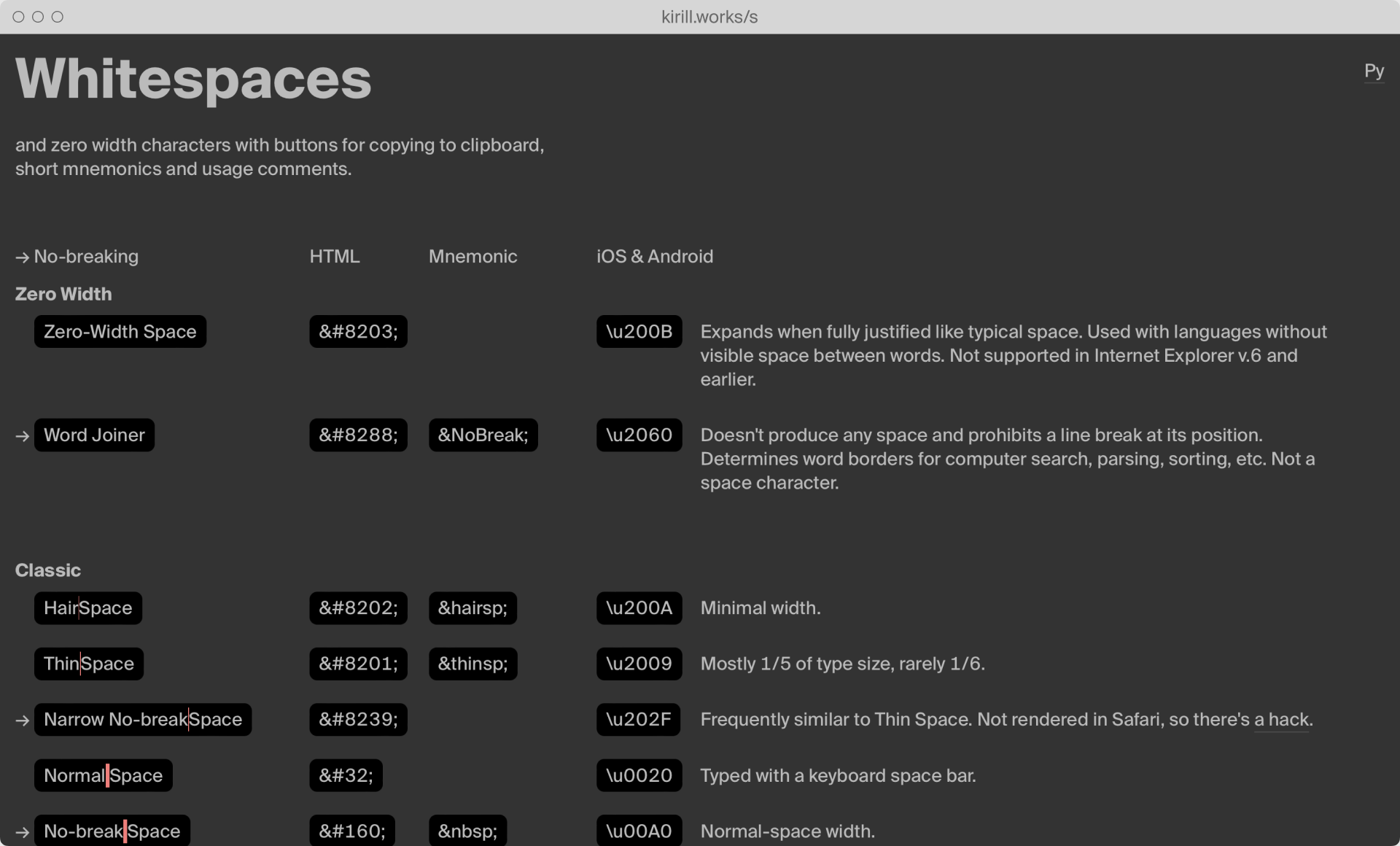
Additionally, I created Pre-logo, a boutique featuring almost-ready high-quality logos. Furthermore, I launched Whitespaceson ProductHunt, a table that enhances typography work with easy copy-and-paste functionality.
The wingspread, Feb 2018... Jan 2020
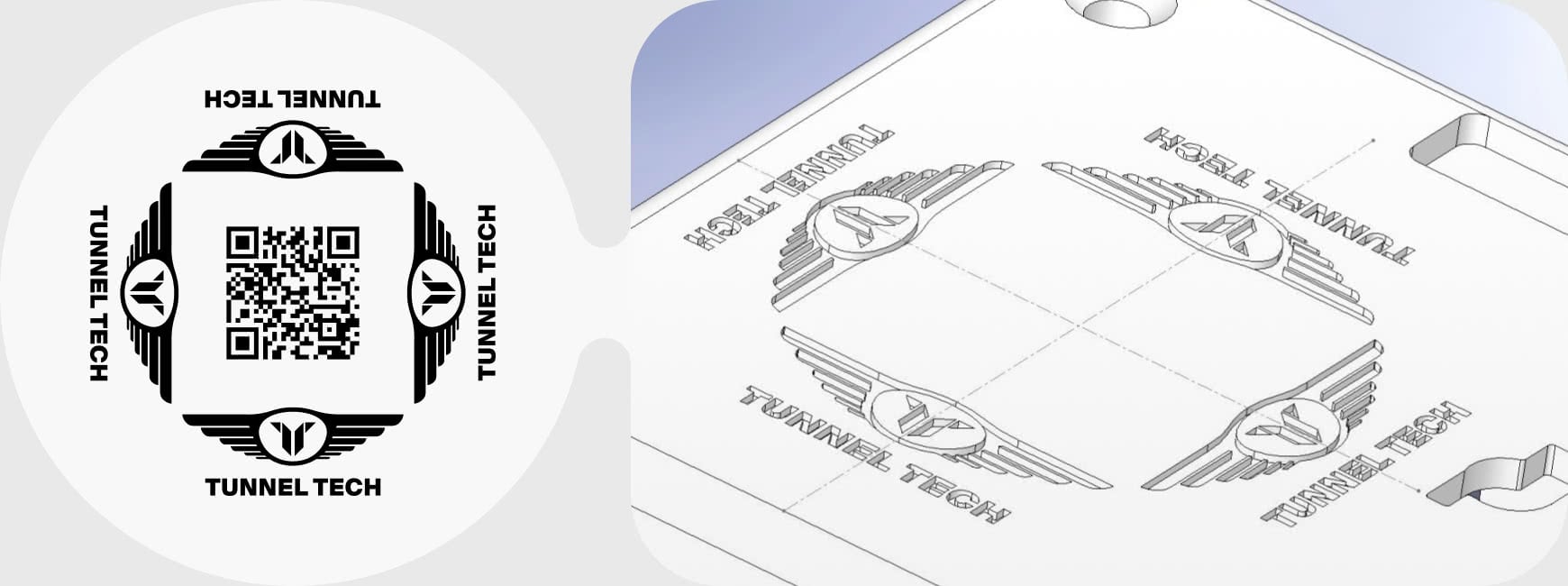
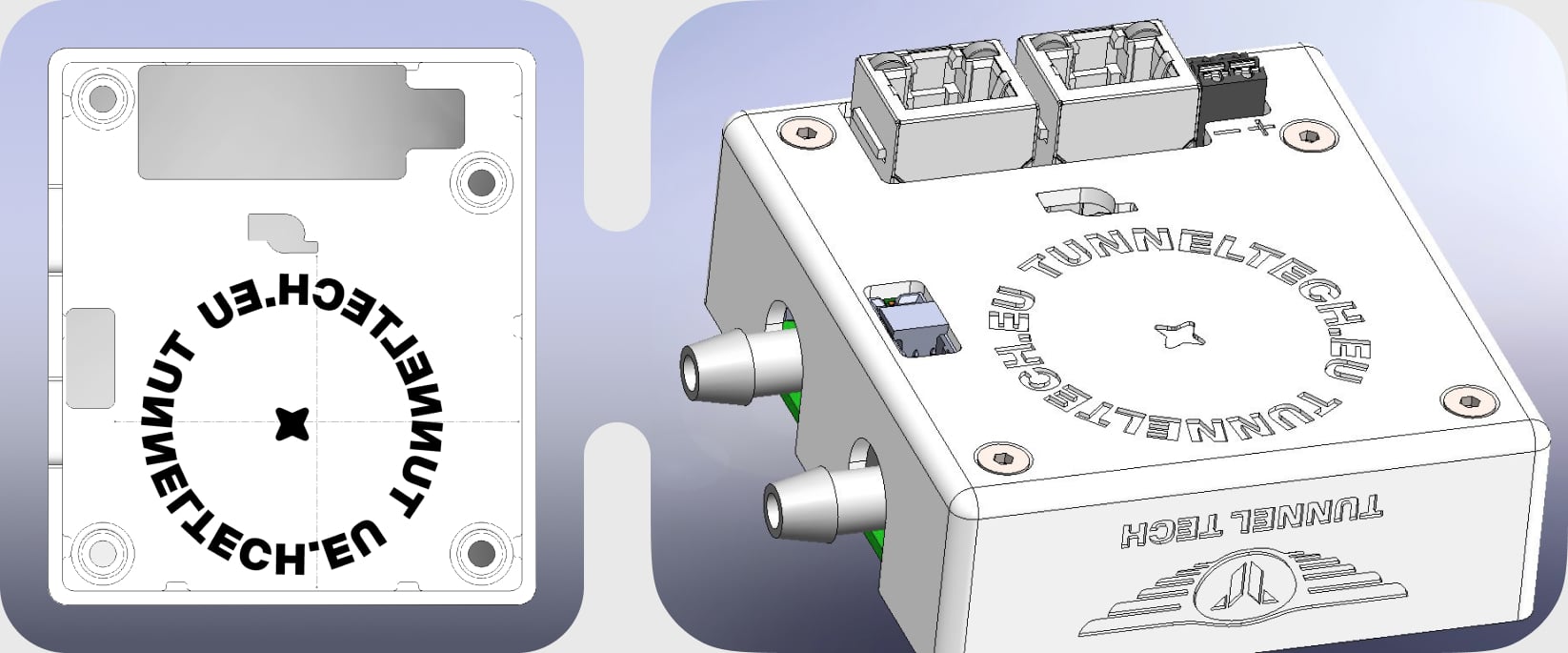
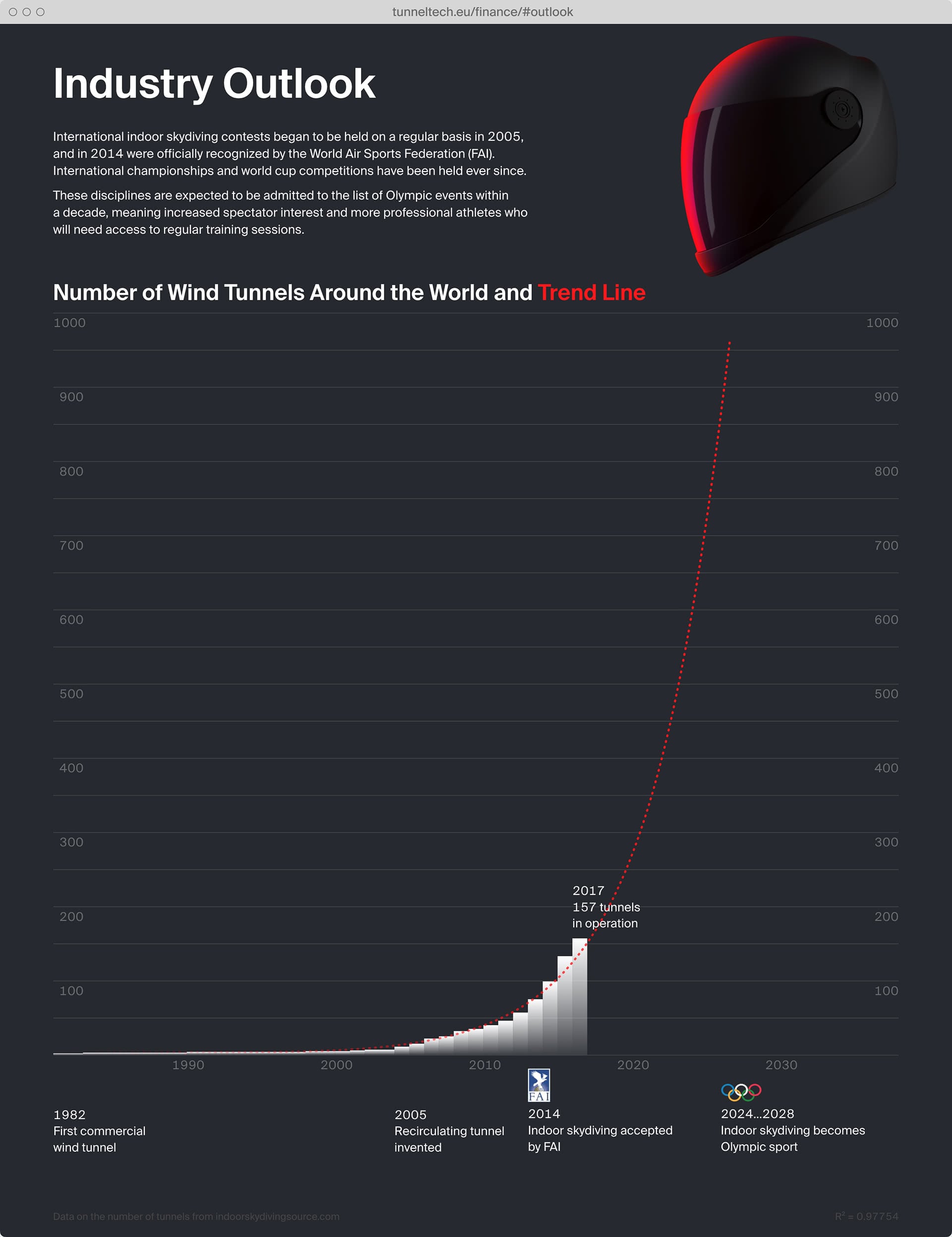
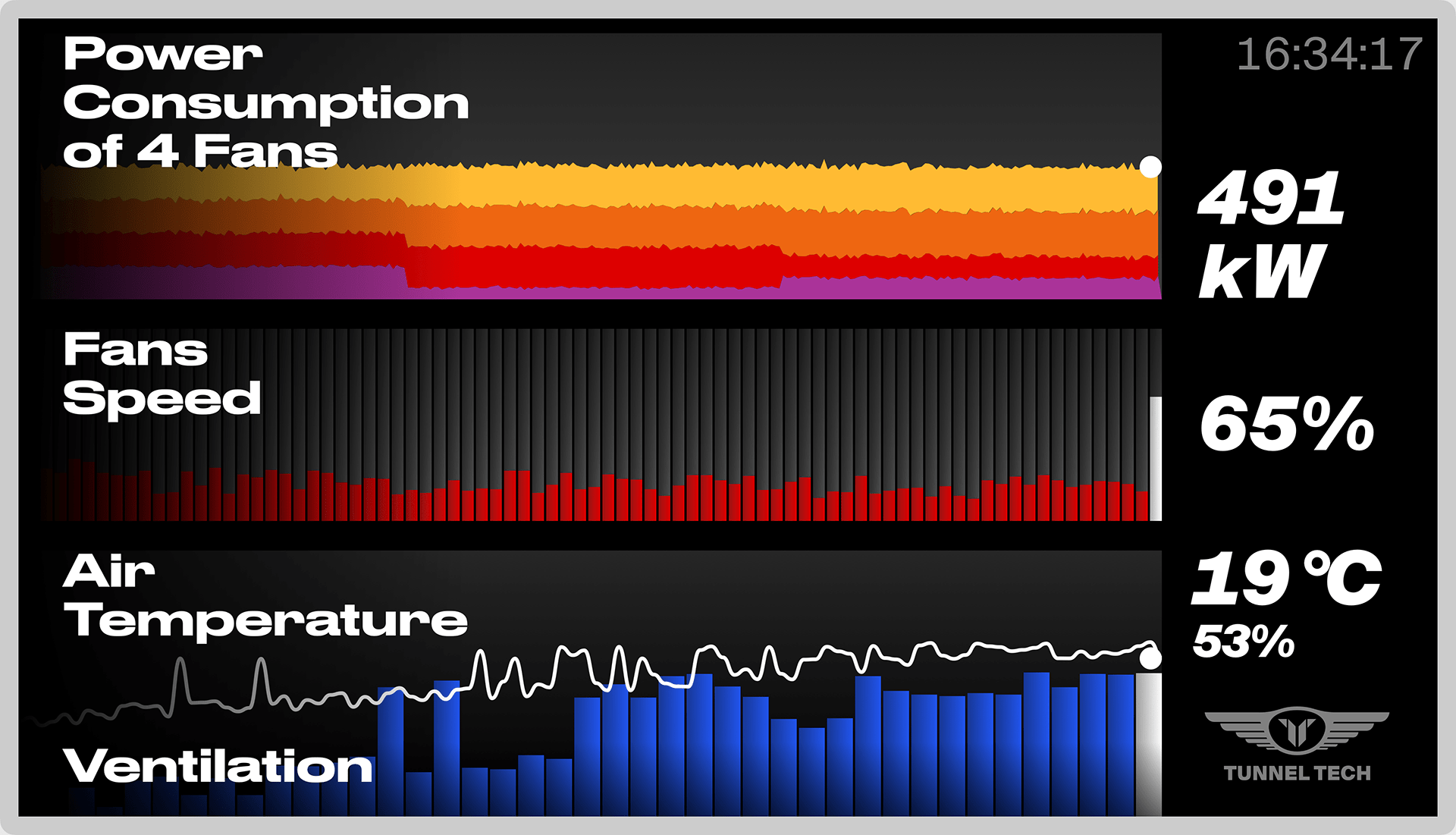
Tunnel Tech is a Russian-German self-designed wind tunnel developer.
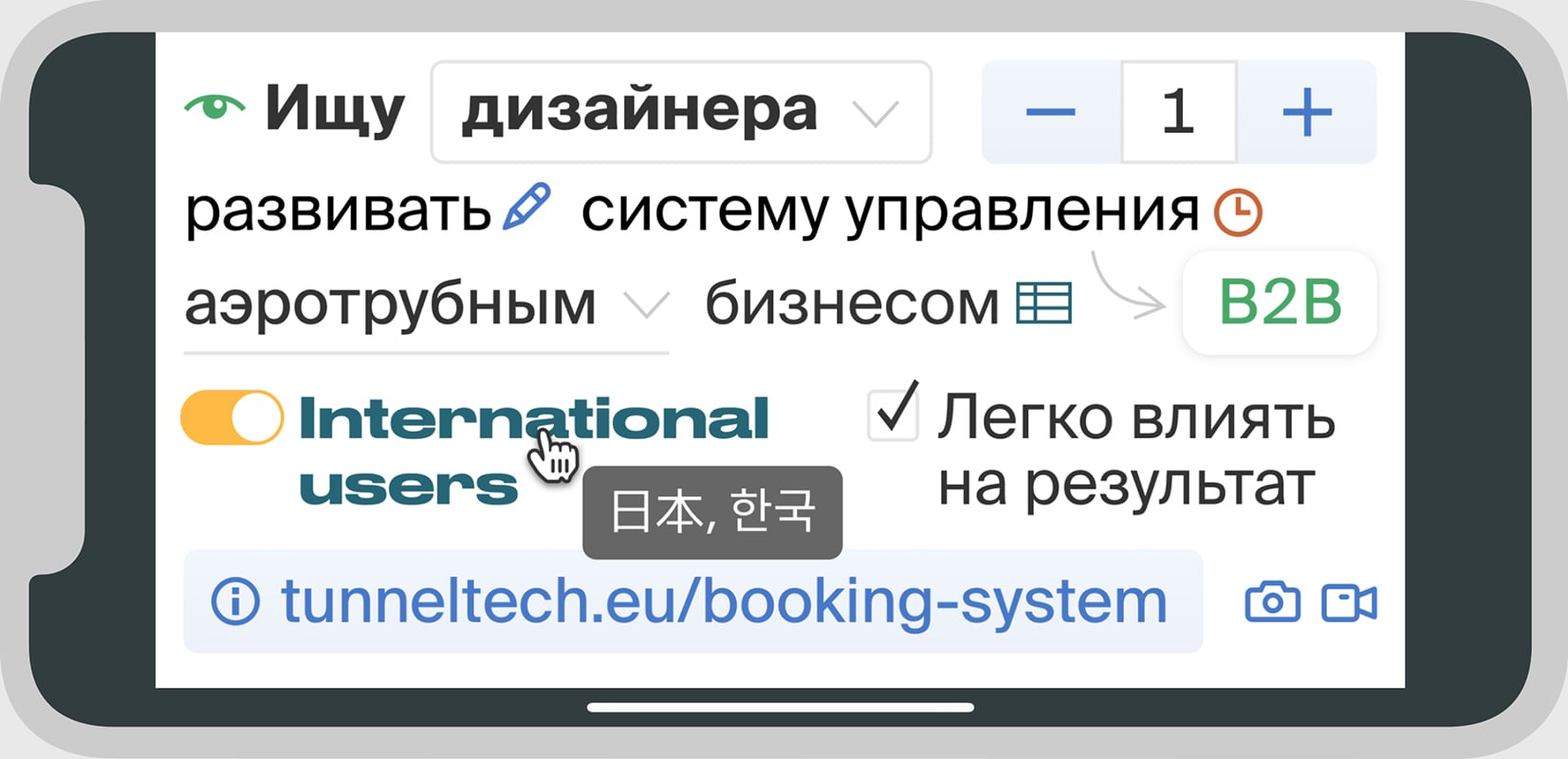
I started as a product designer for booking system and ended up as an art director translating the company's corporate and product ambitions into a bold visual language. I also helped to scout for designers to hire and collaborate.
Tunnel Tech website.
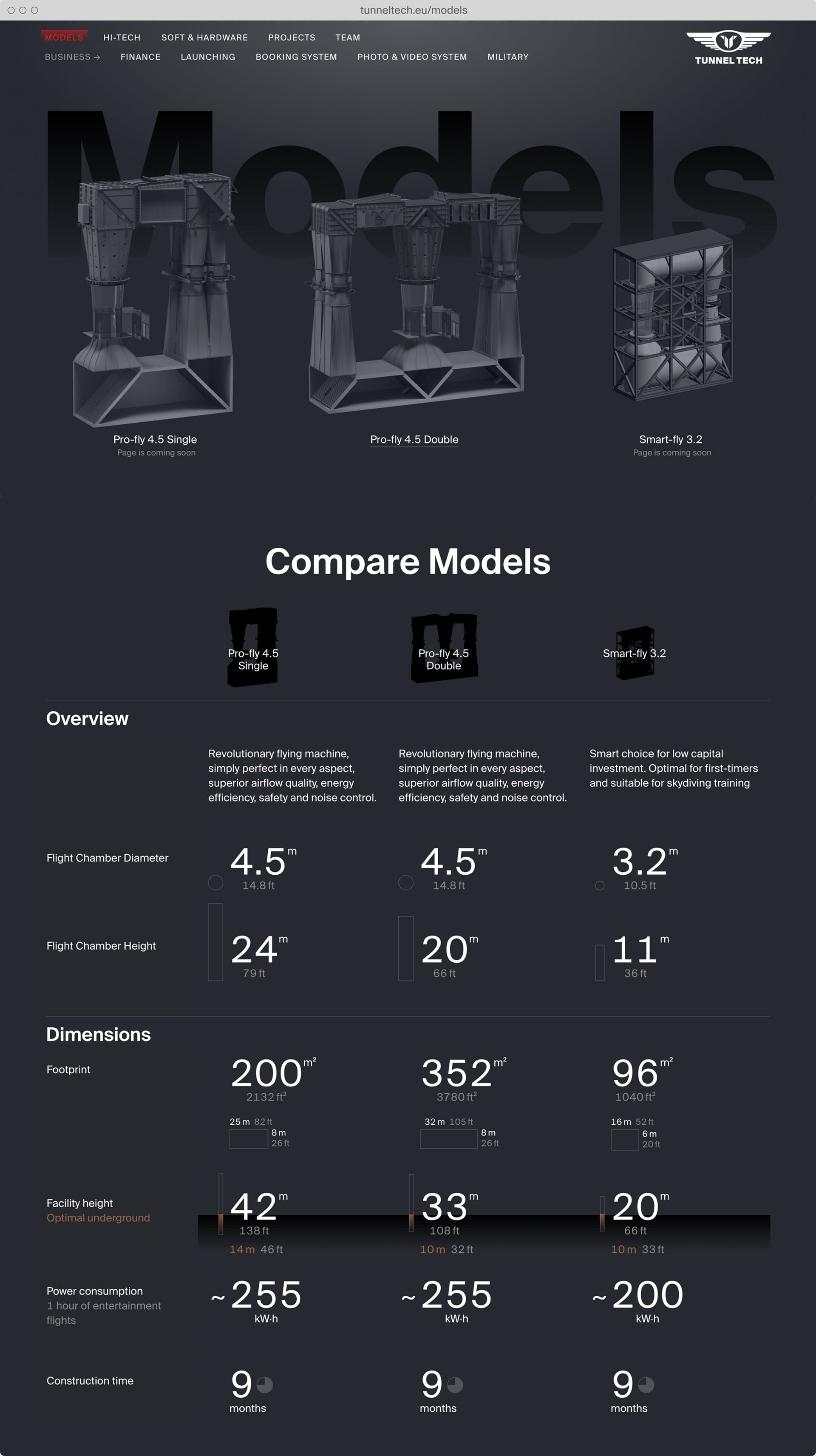
Experience design for two new hardware products: software design and hardware design consulting for the engineering team.
Rendering...
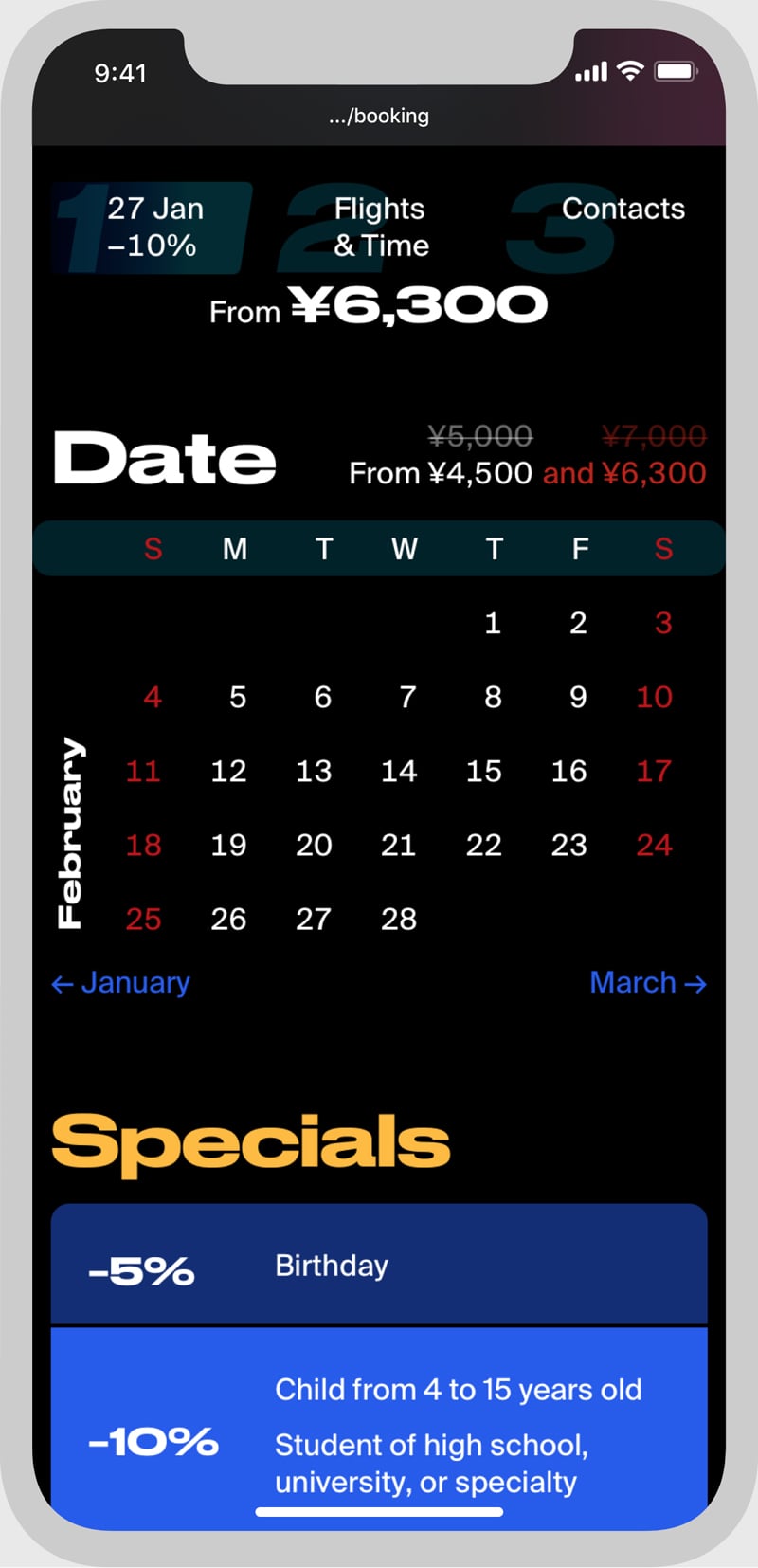
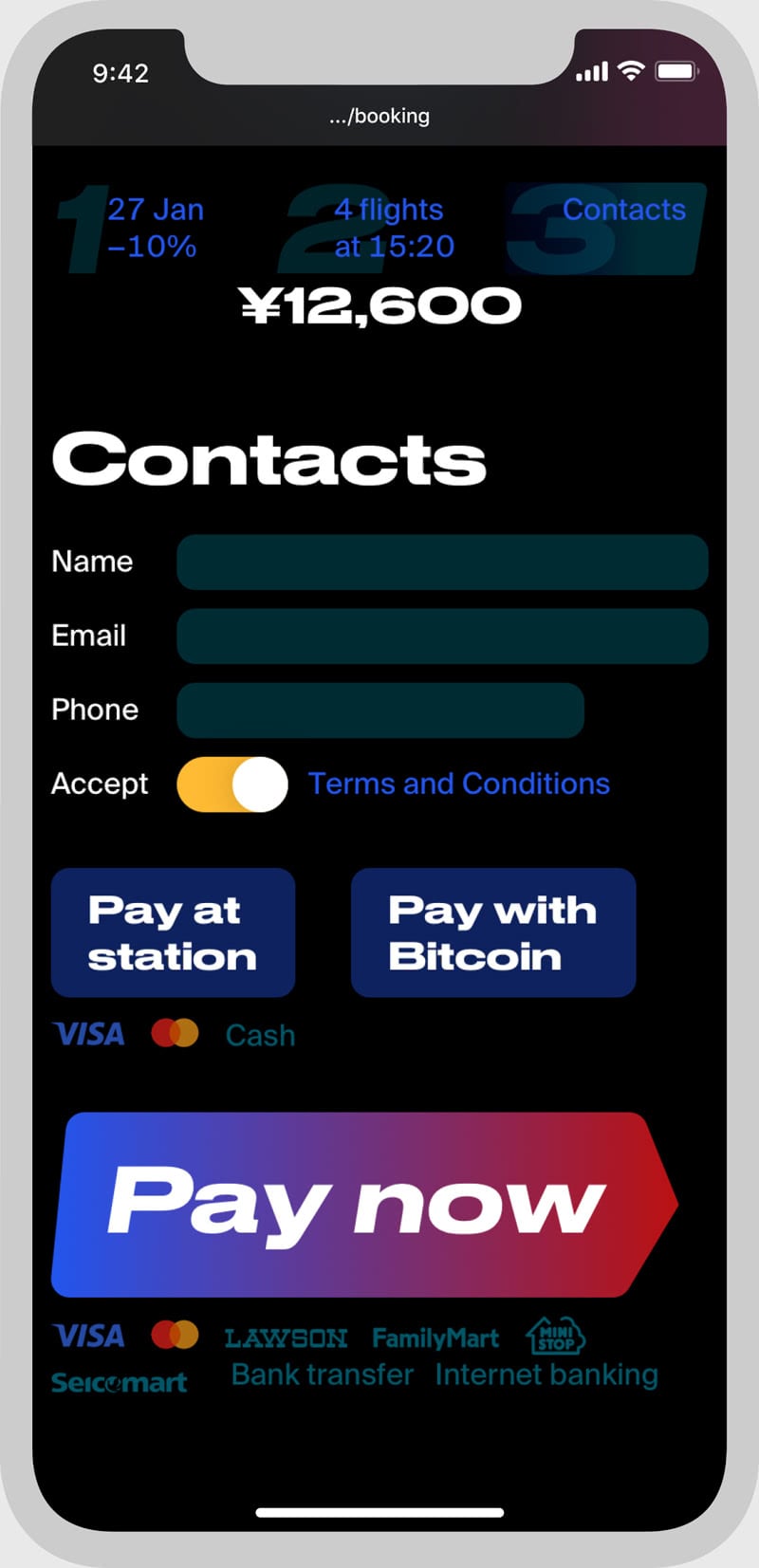
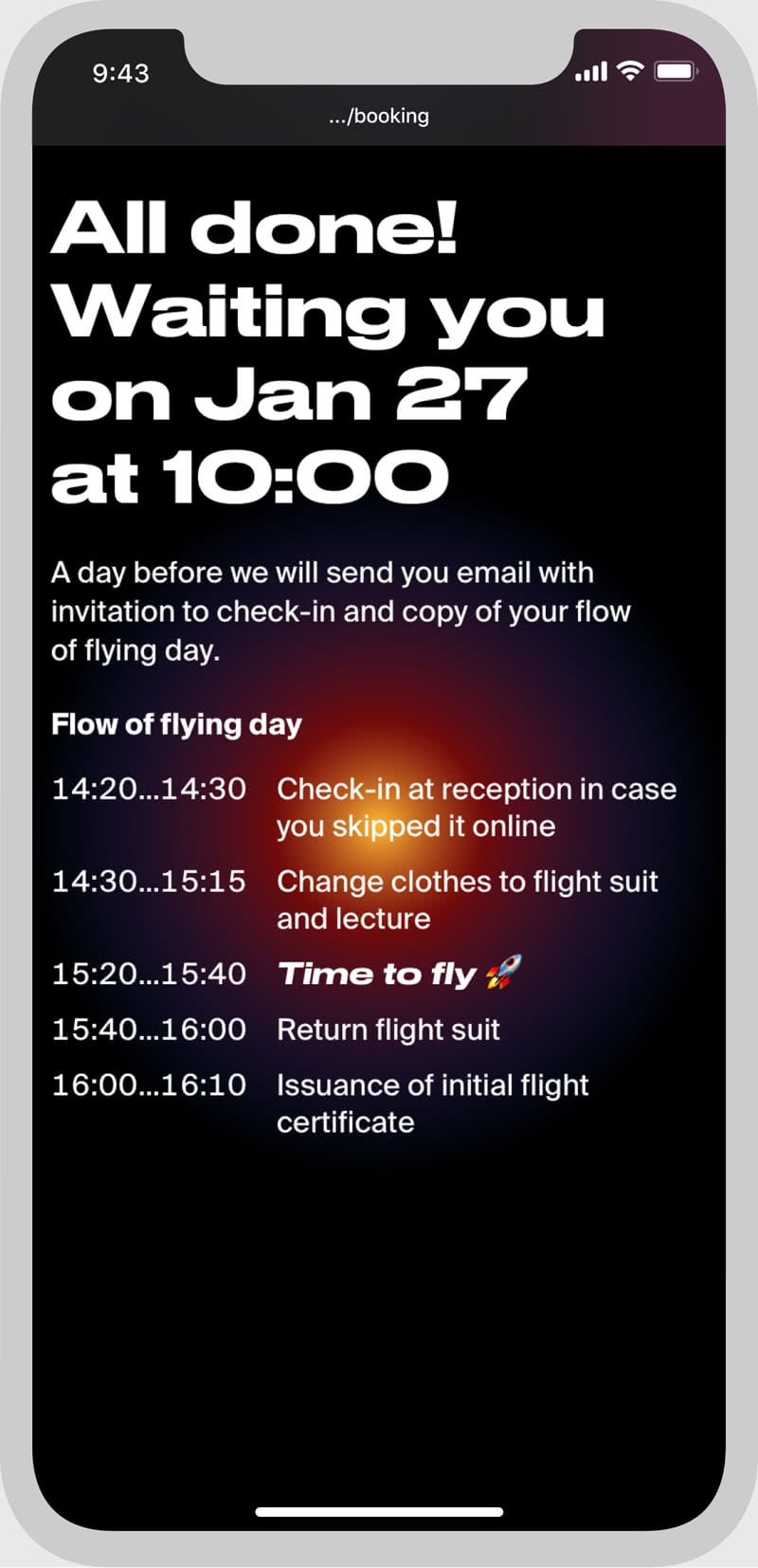
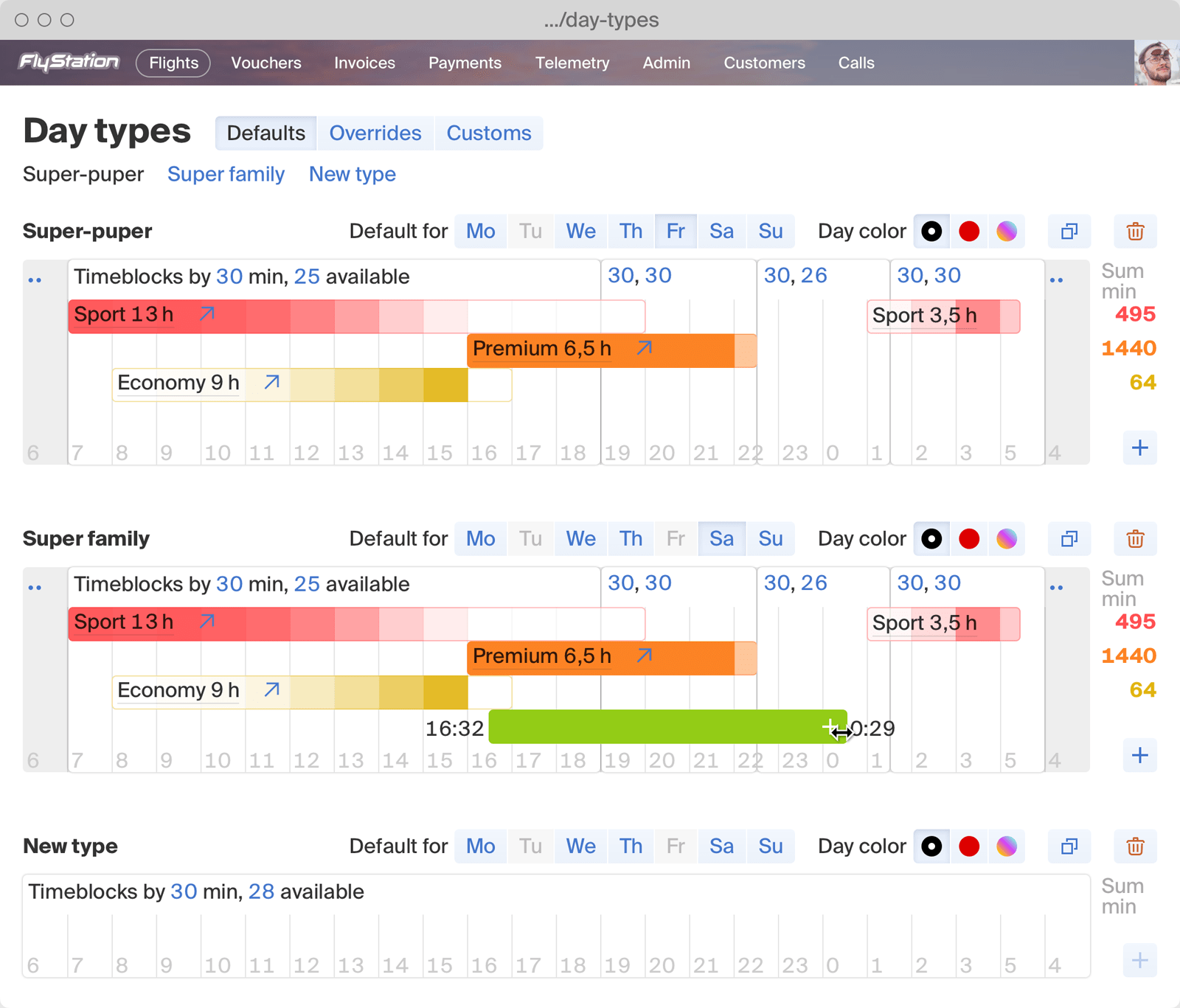
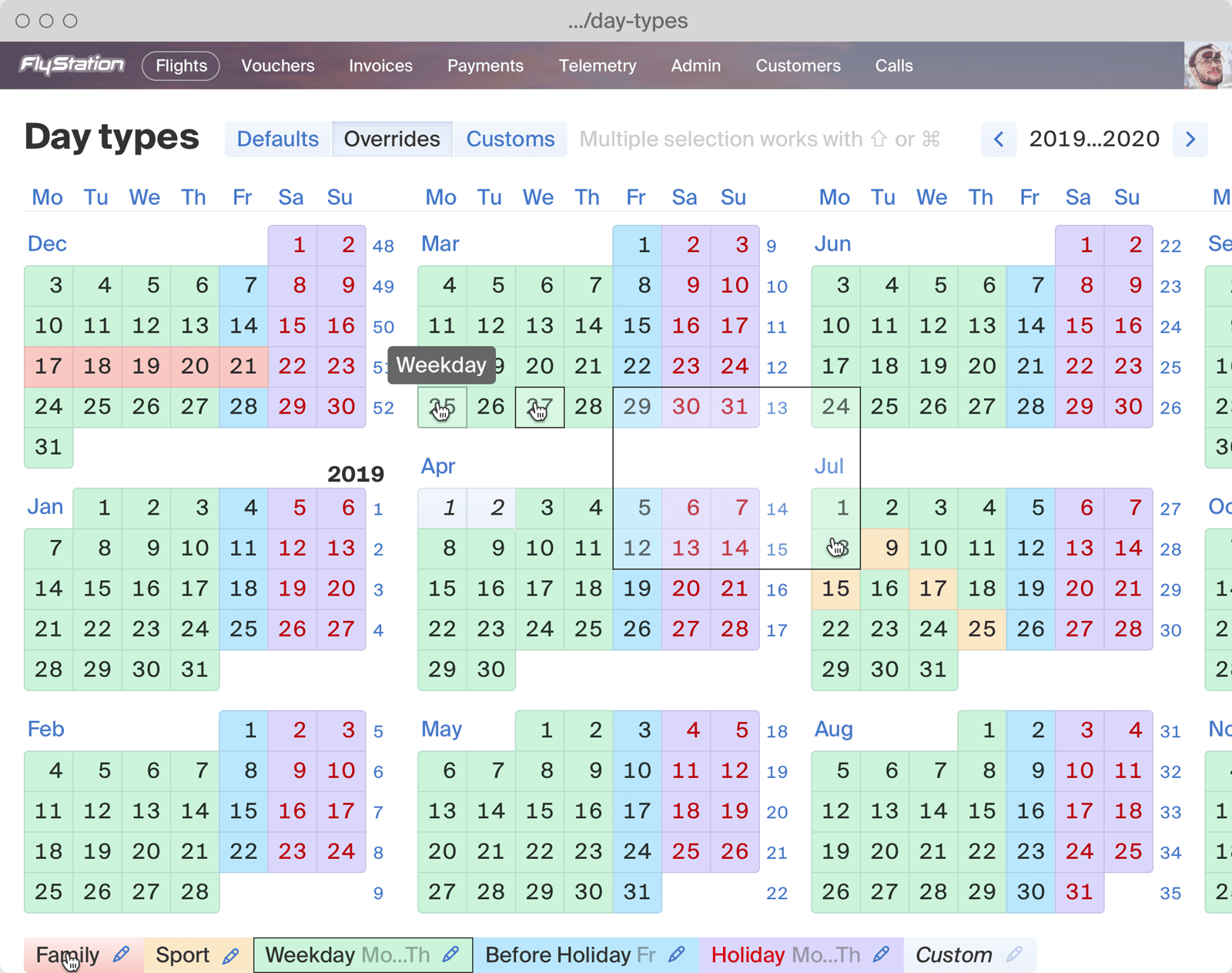
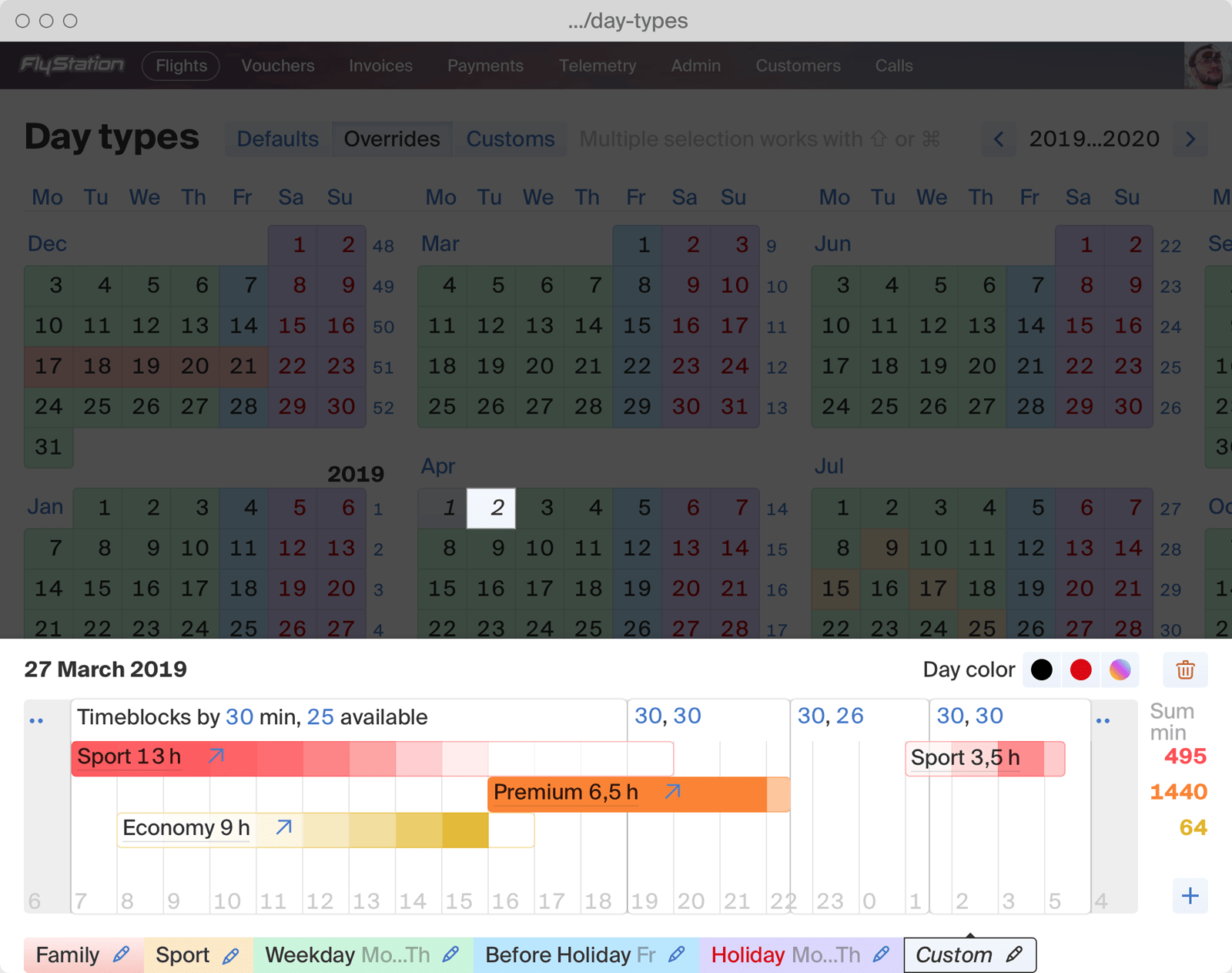
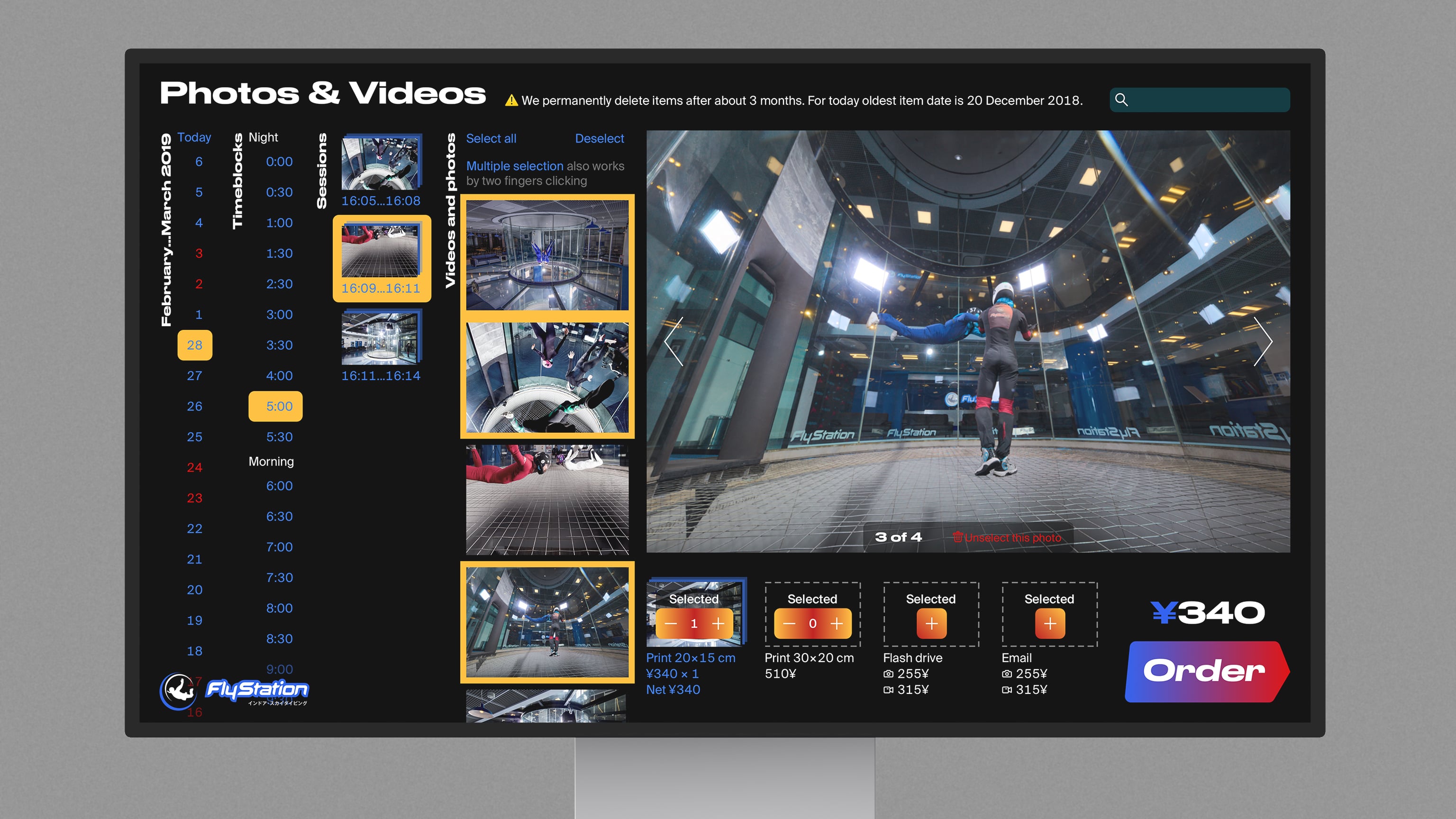
Indoor skydiving booking system, including web widgets, gift vouchers, and emails.
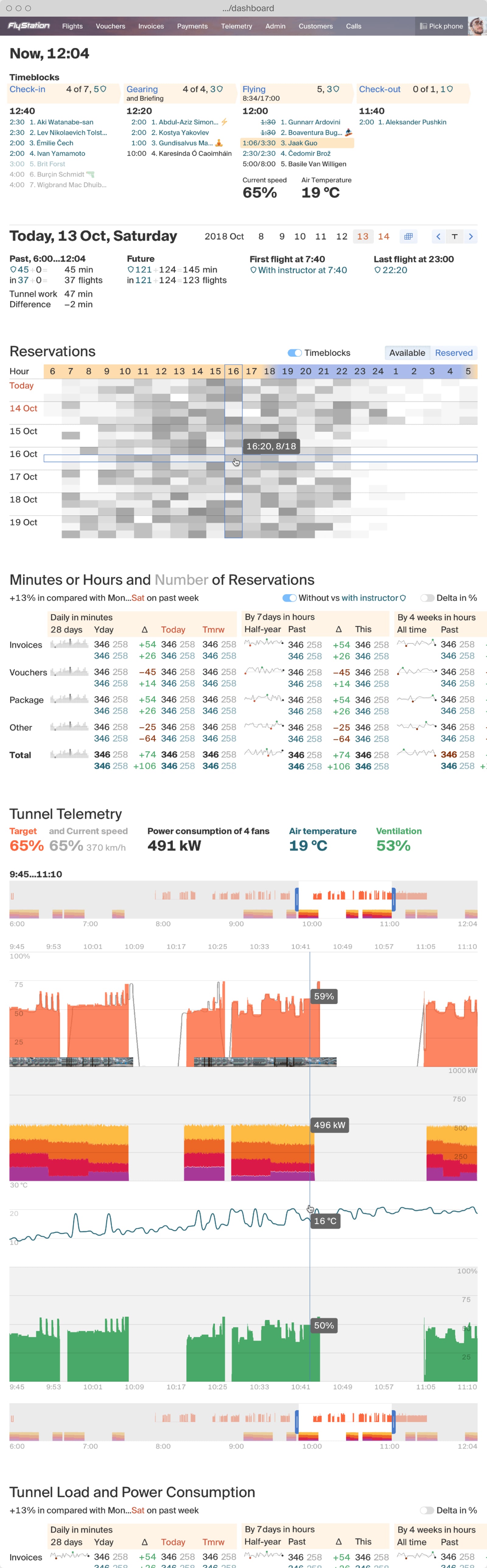
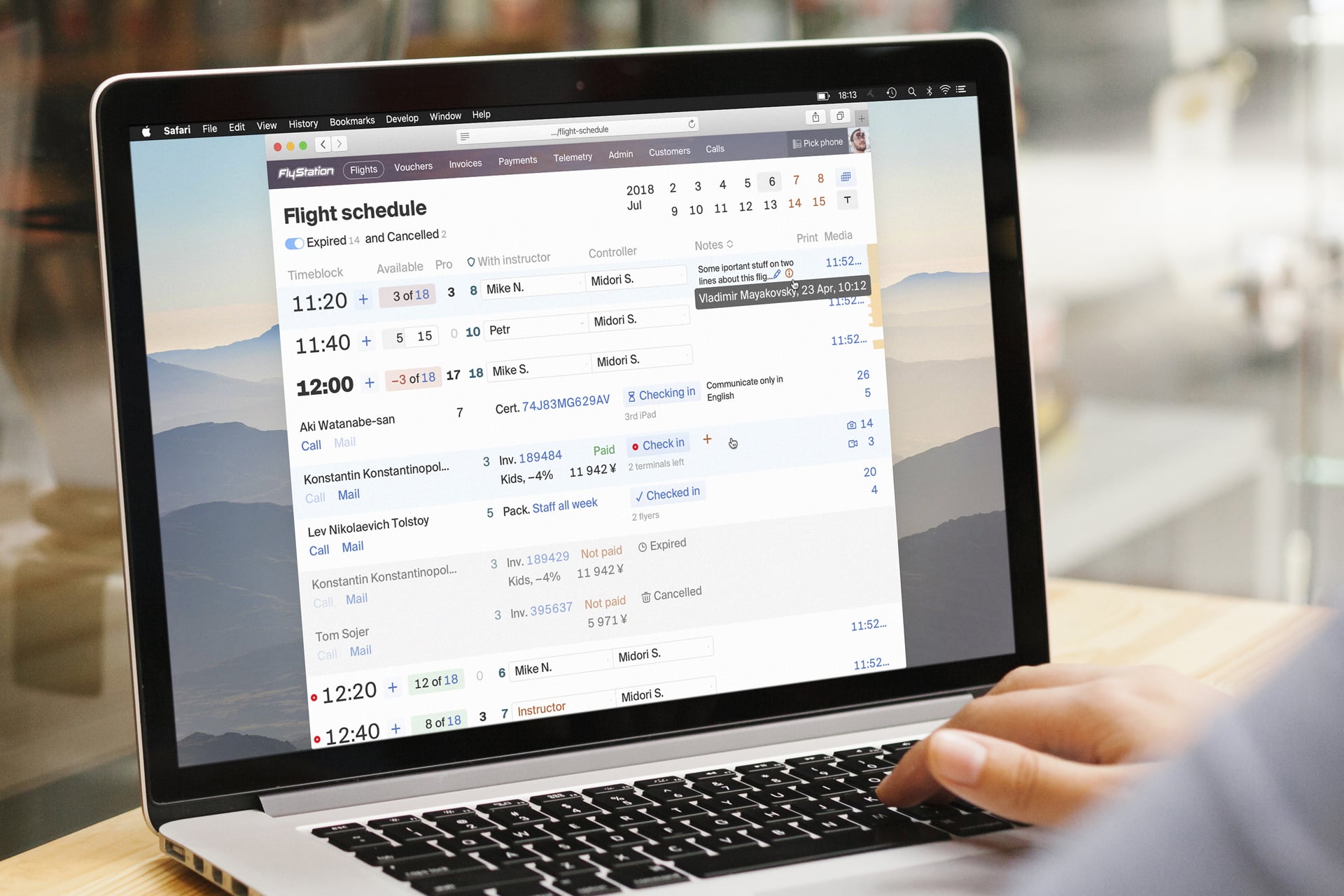
Indoor skydiving facility admin software.
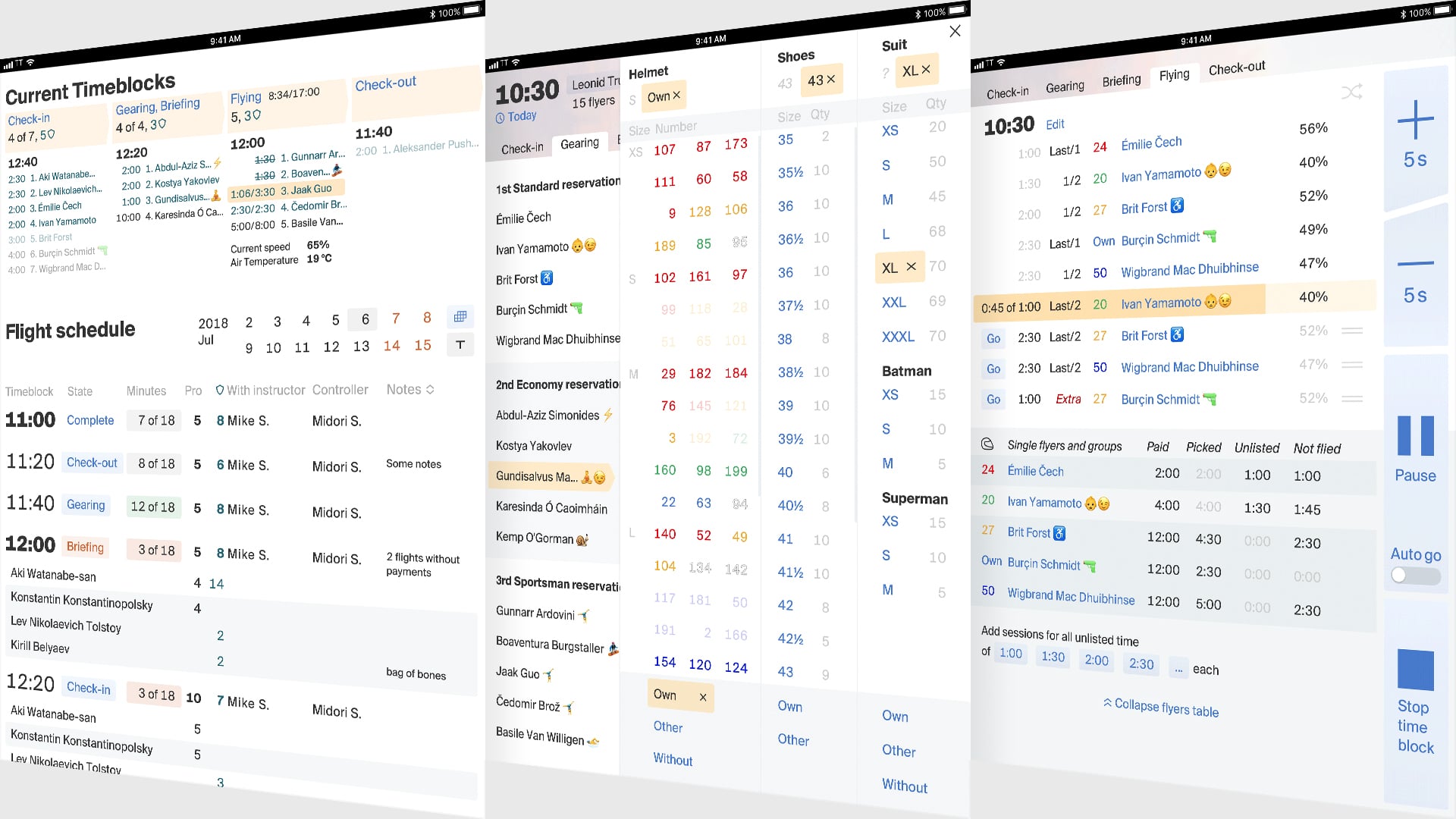
Tablet app for tunnel instructors helping clients control their business flows.
Screens for public areas and an interactive kiosk for better customer experience.
Dream about 100% definition, Apr 2015... Oct 2017
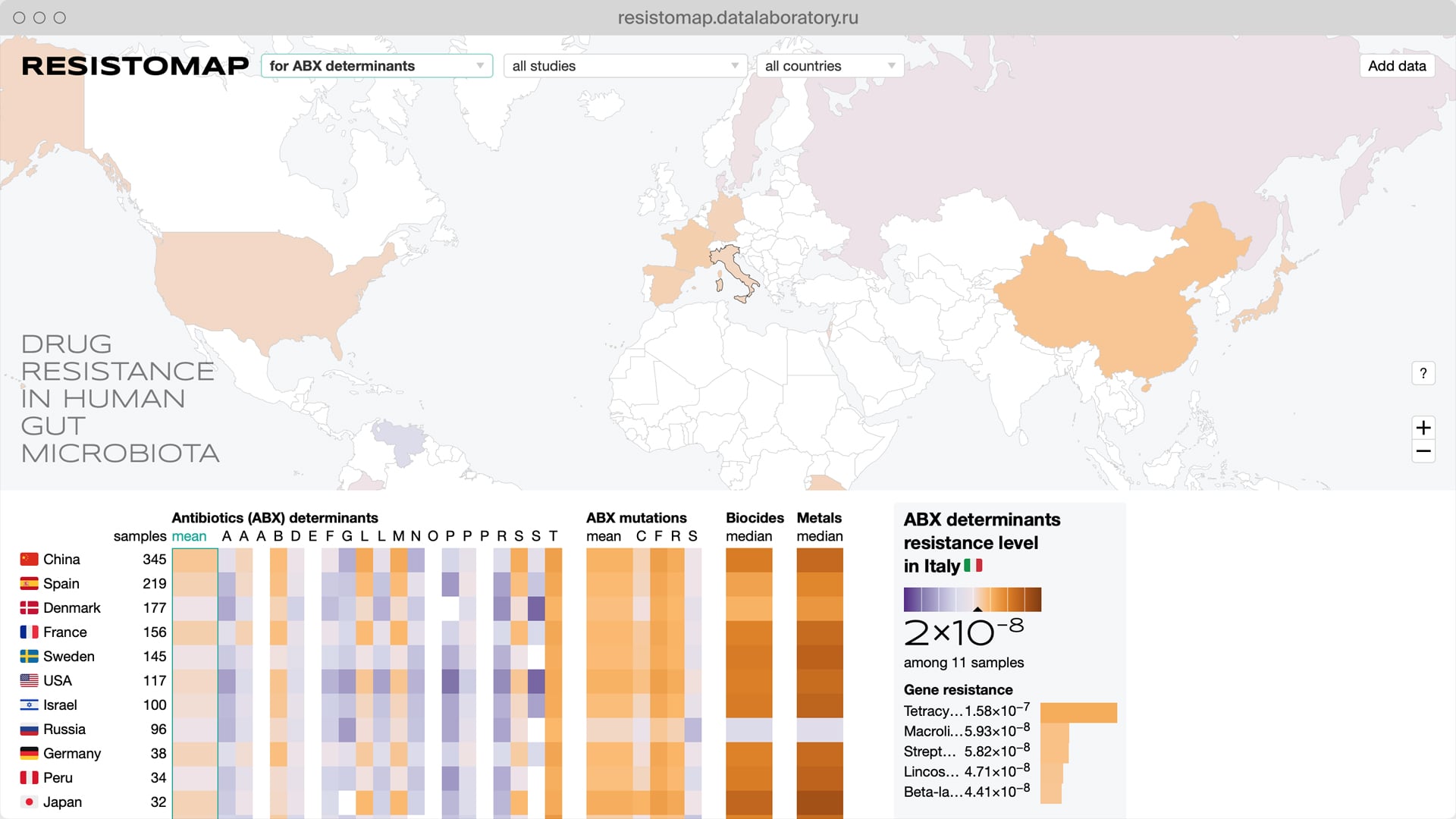
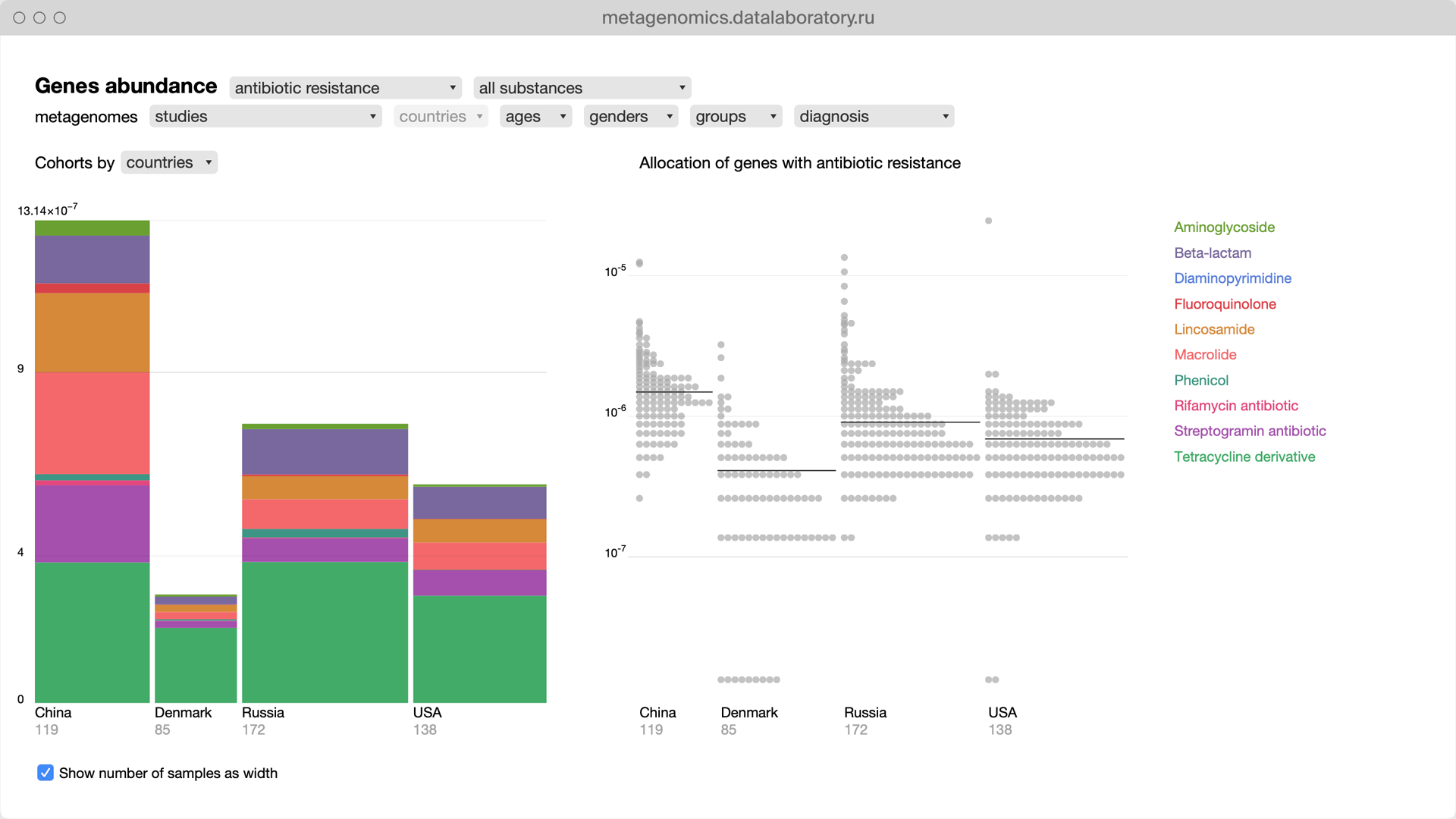
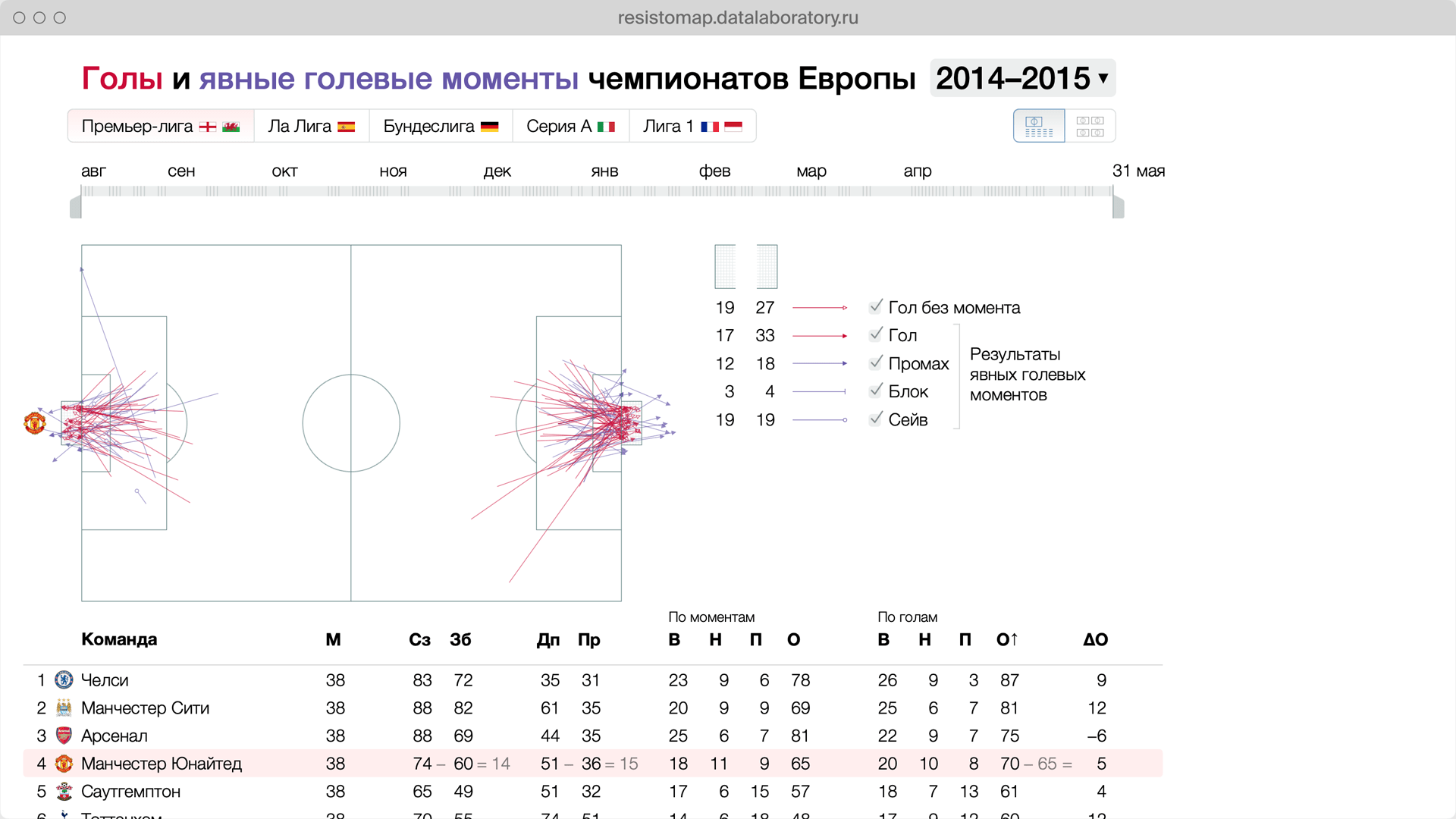
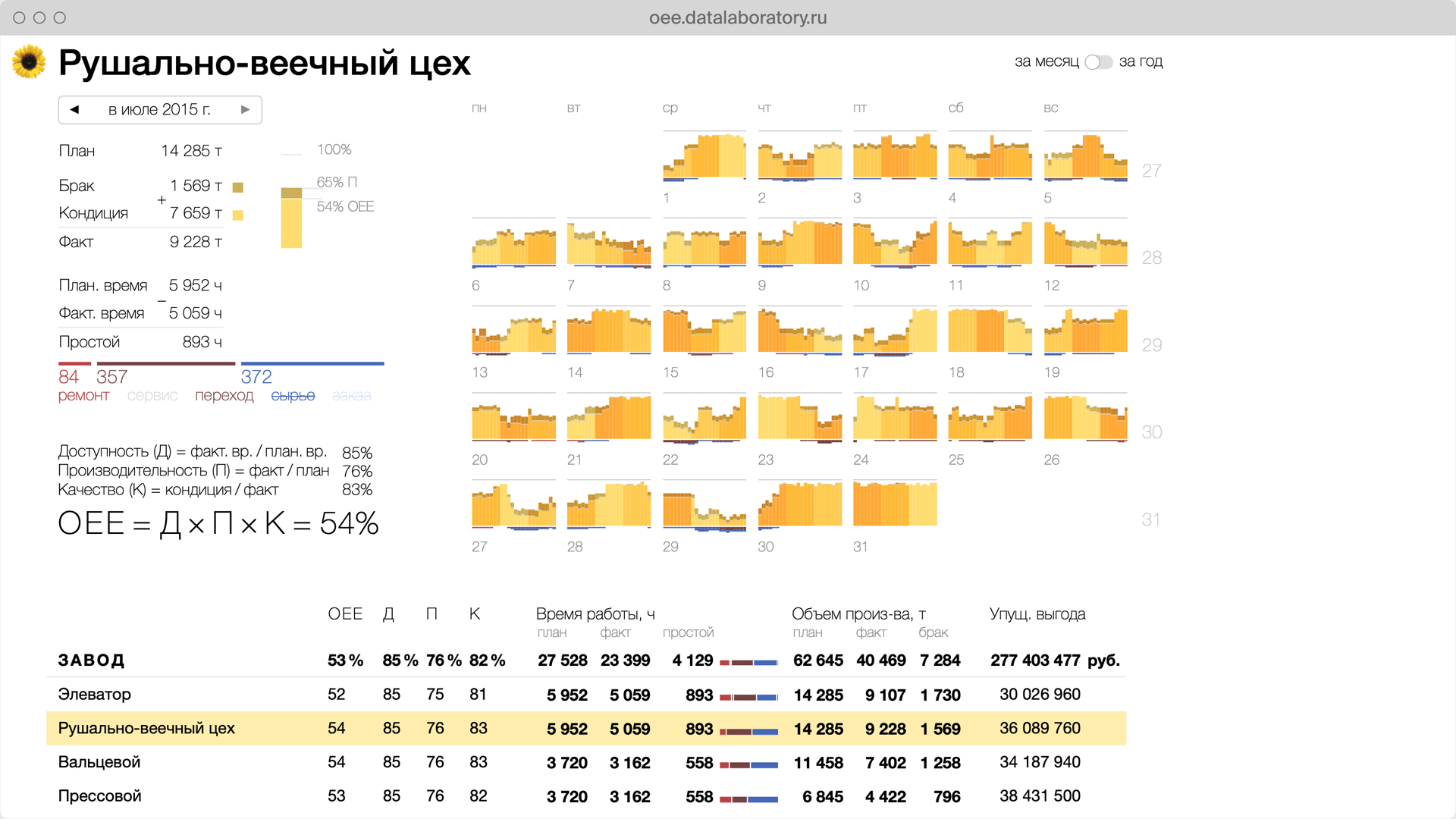
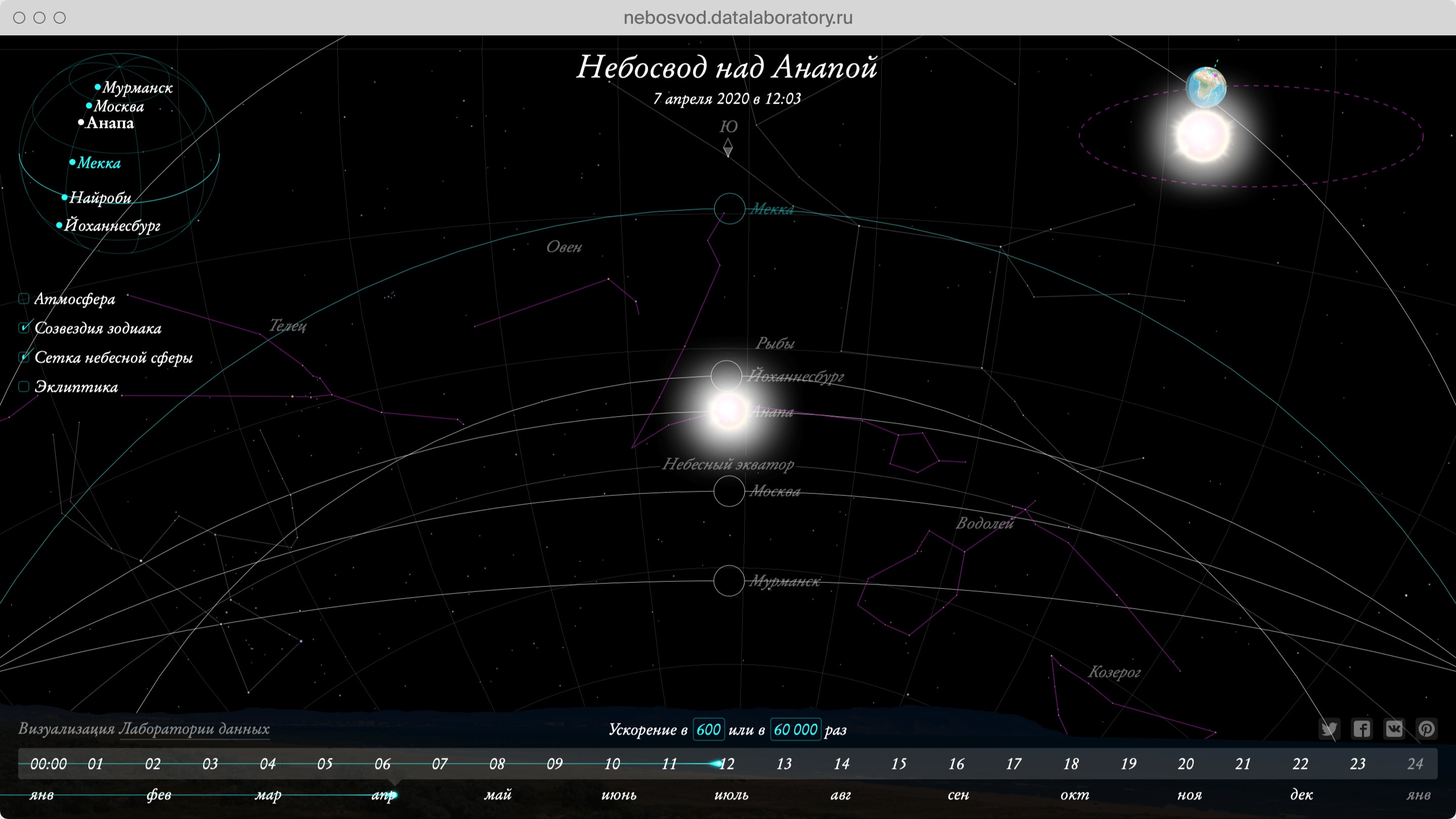
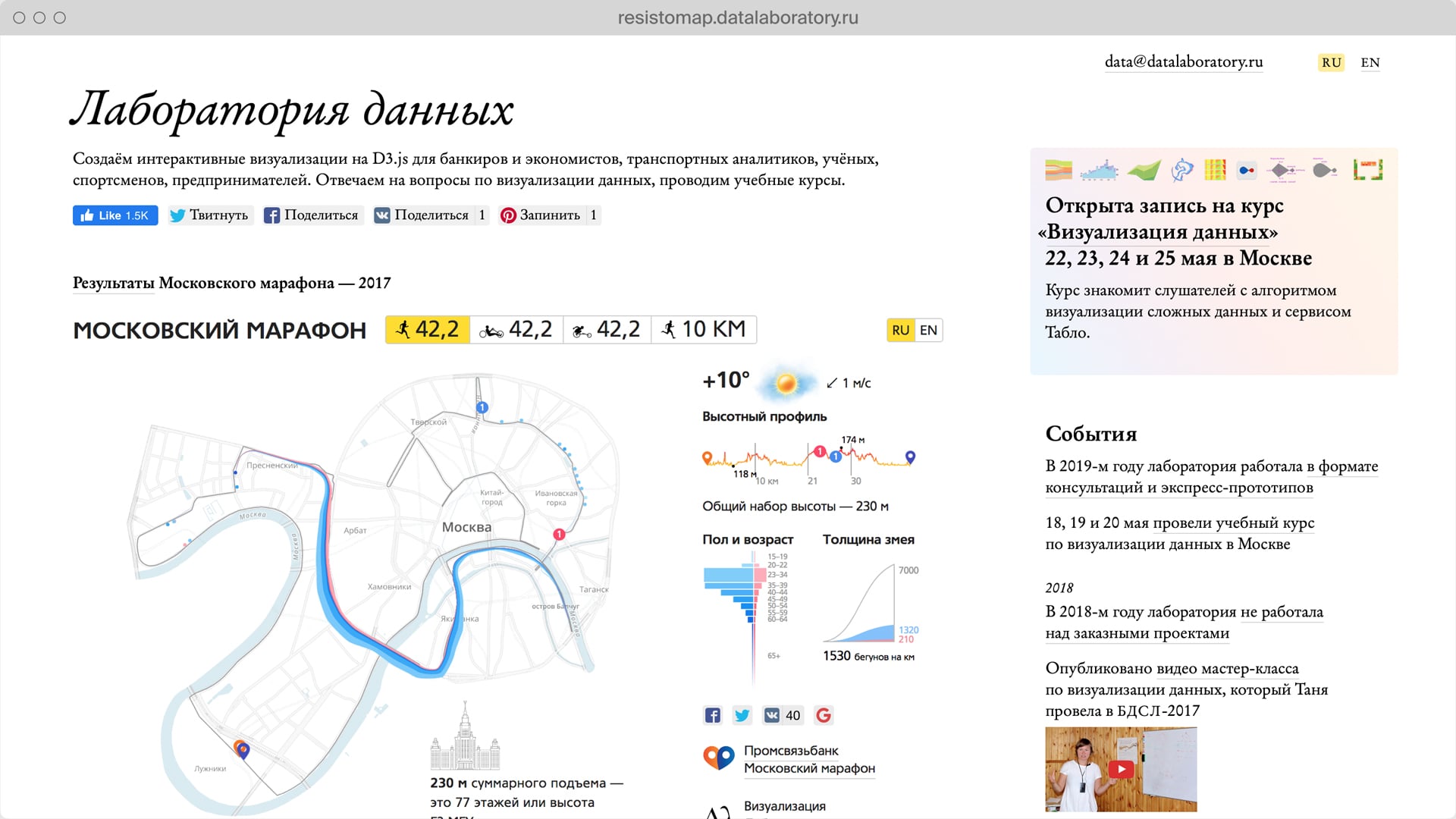
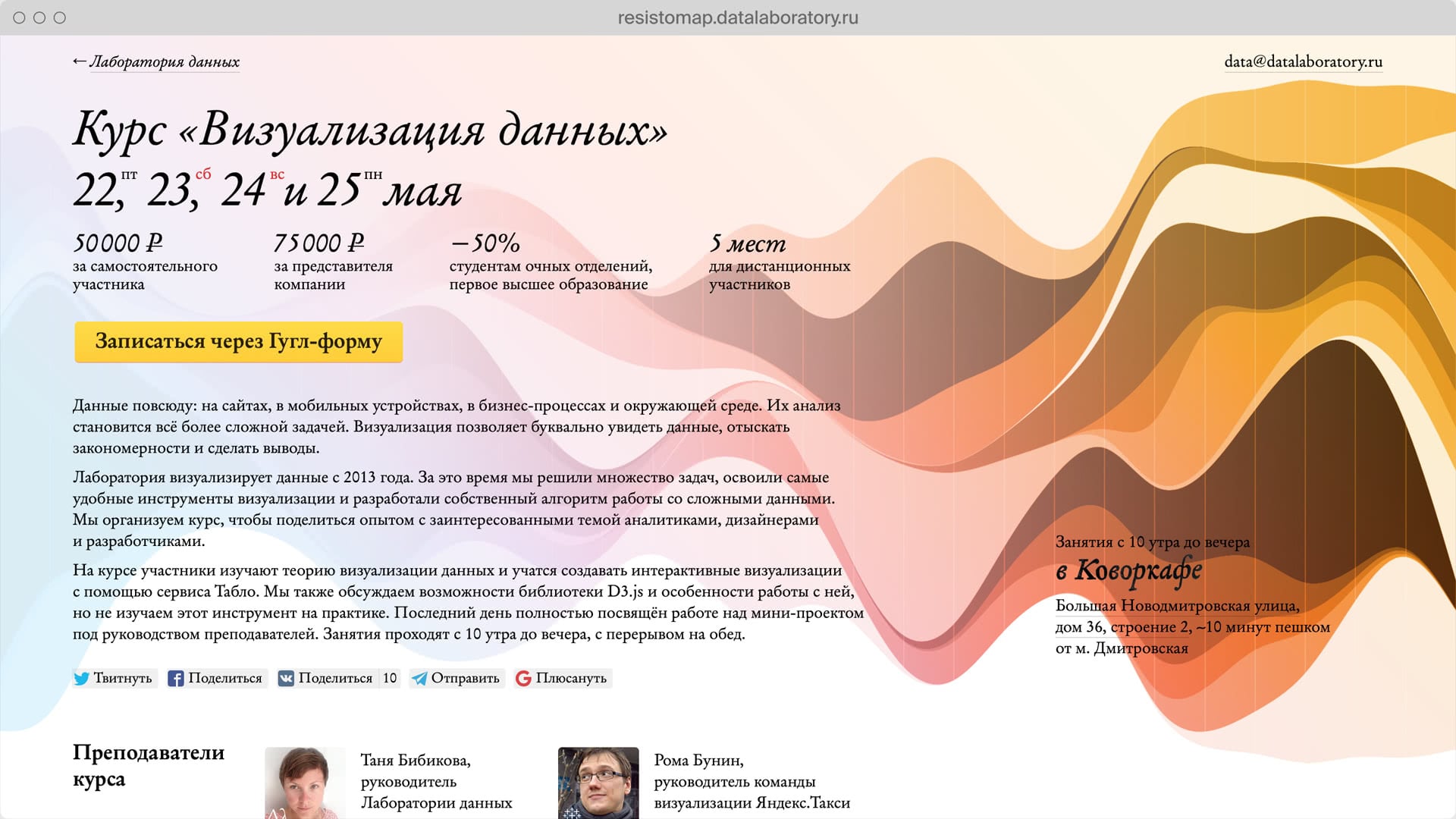
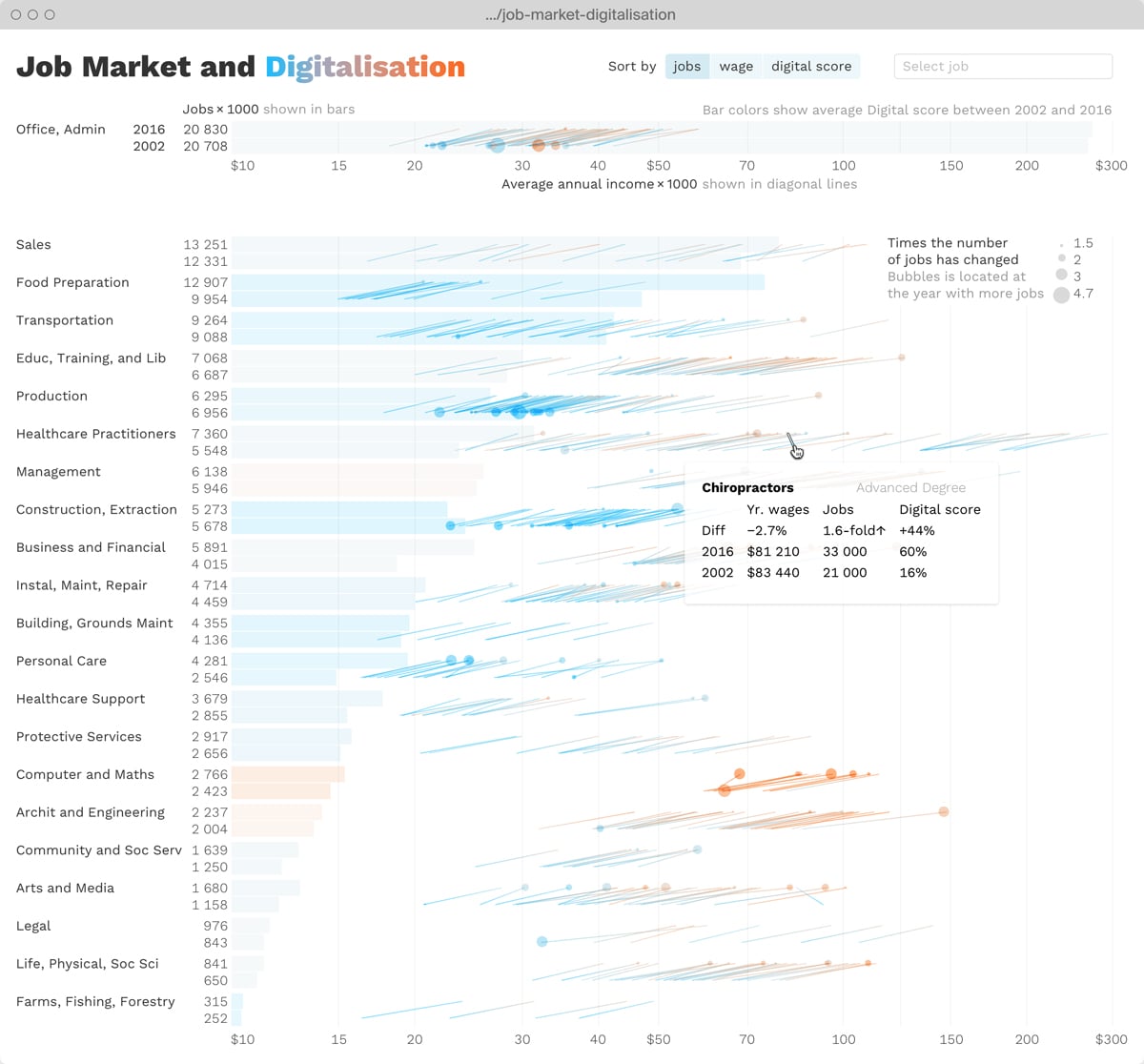
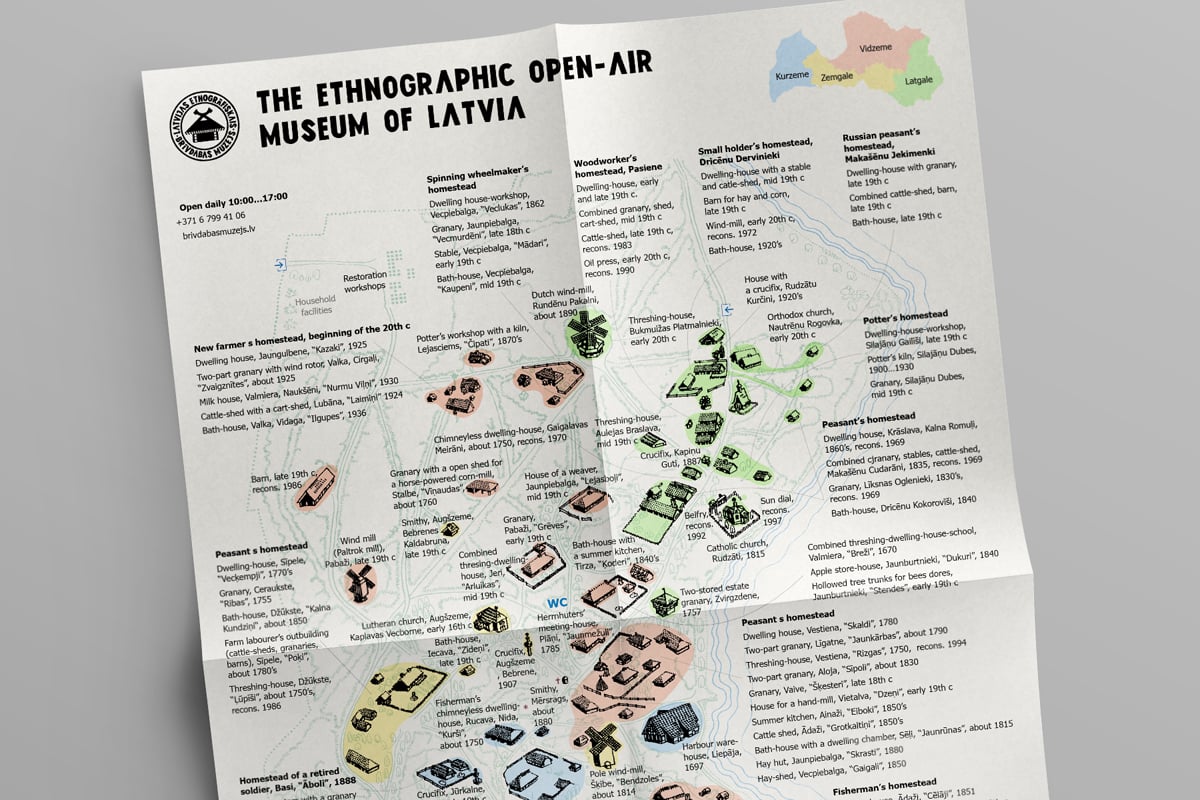
Data Laboratory is a major independent Russian data visualization studio.
I worked as a senior designer and my main focus was avoiding any kind of information ambiguity in our projects.
Product design for a financial analysis web app.
Data Laboratory client and educational projects.
New visual identity for the Laboratory.
While working for Data Laboratory I wrote a number of articles on dataviz and UI analyses and created redesign concepts.
Why not try again? May 2014... Apr 2015
We reopened Kipo studio with my wife Polina from scratch. This time we brought in new skills, better processes and outsourced web development management.
With a new baby coming in, we’ve closed the venture, as I couldn't manage the business on my own.
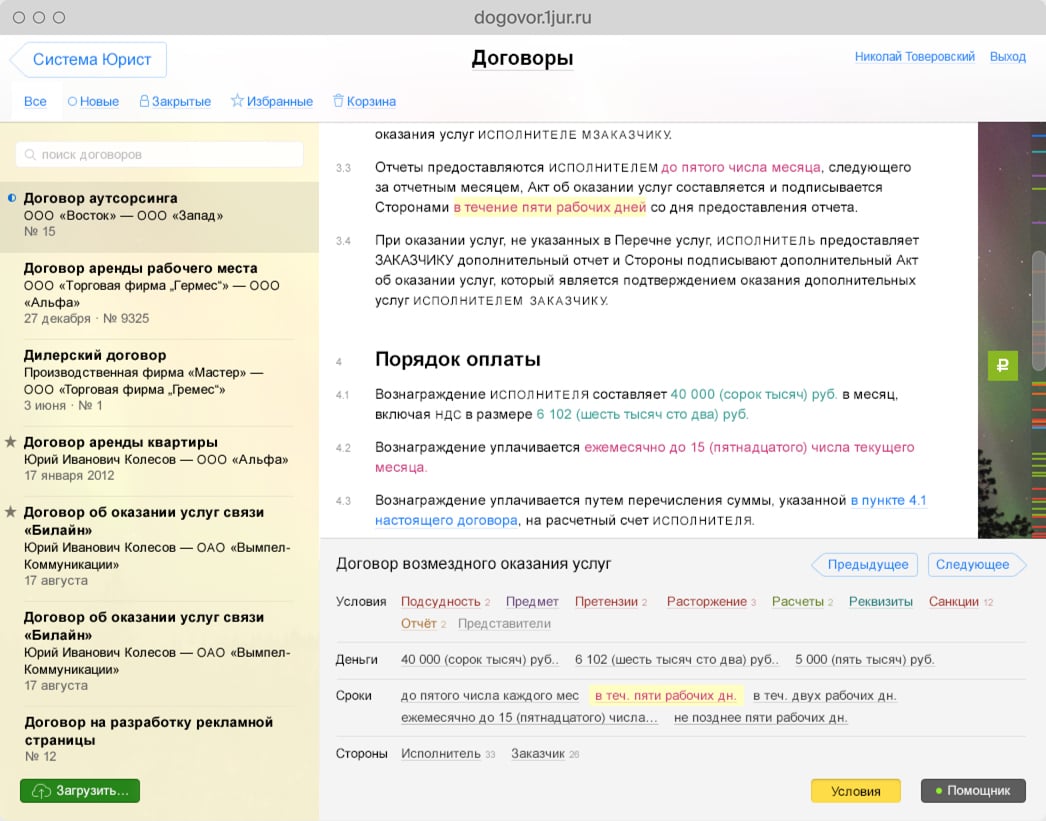
How to do The Humane Interface, Sep 2013... May 2014
Bureau Gorbunov is one of the major Russian design studios, specializing in user interfaces and implementing TRIZ in their design process.
I worked as junior designer growing as fast as I can. My main project was a UI design for a legal web app.
I did everything: client acquisition and communication, accounting, design. We were good at visual identities, printed matter and illustrations, but didn’t know how to prove the value of design for clients.
Misunderstanding of world’s scale, Sep 2009... Jun 2011
M-Quadrat studio is a local studio, where I started my design career.
I worked on logotypes, printed matter, outdoor advertising and first tried myself in digital design.
Great Opportunity to meet Matisse, Sep 2003... Apr 2009