Разбор визуализации о смертности от огнестрела
Сегодня разберу работу Бена Кассельмана, Метью Козлина и Рубена Фишера-Баума для Five Thirty Eight о смертности от огнестрельного оружия в США.
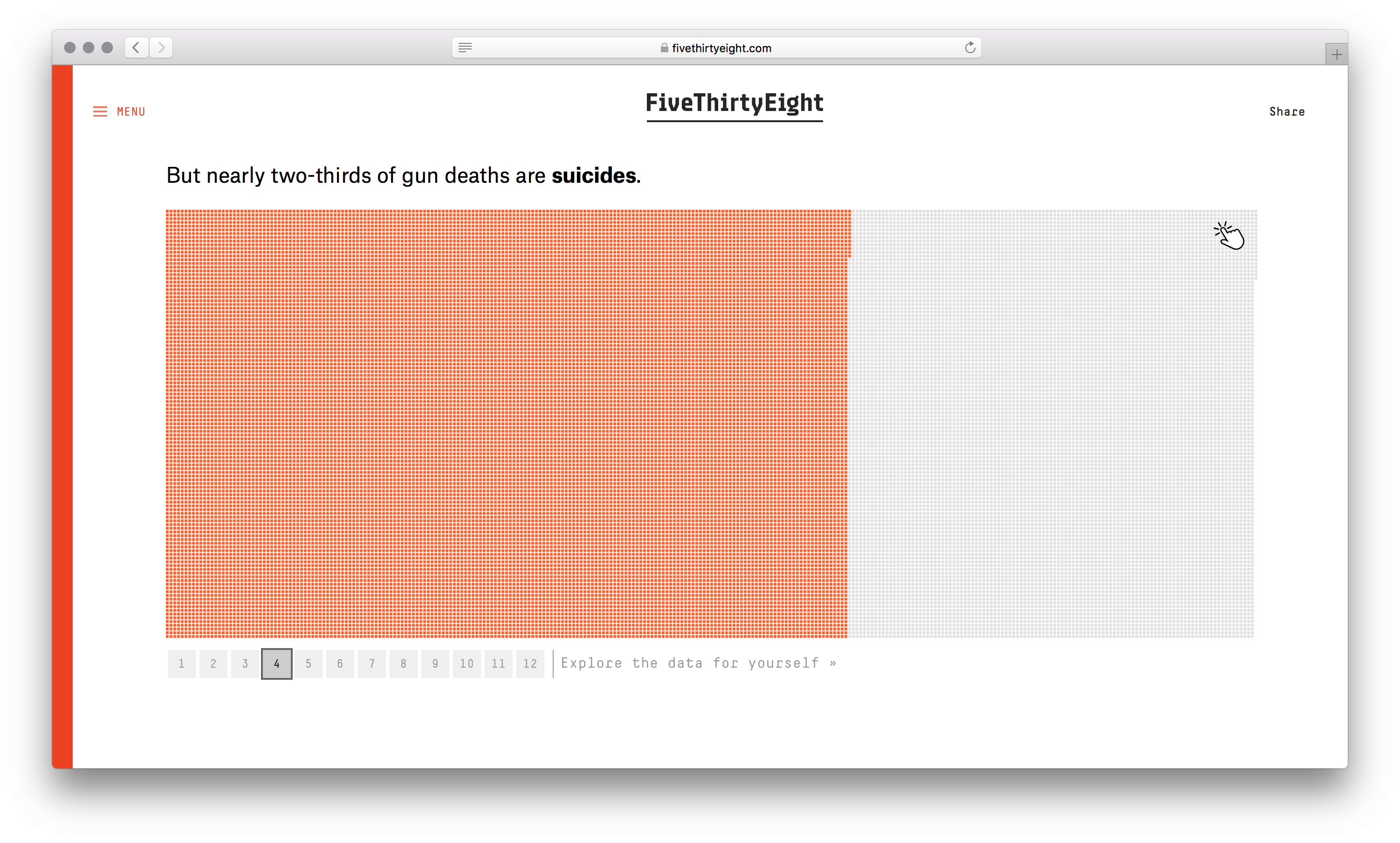
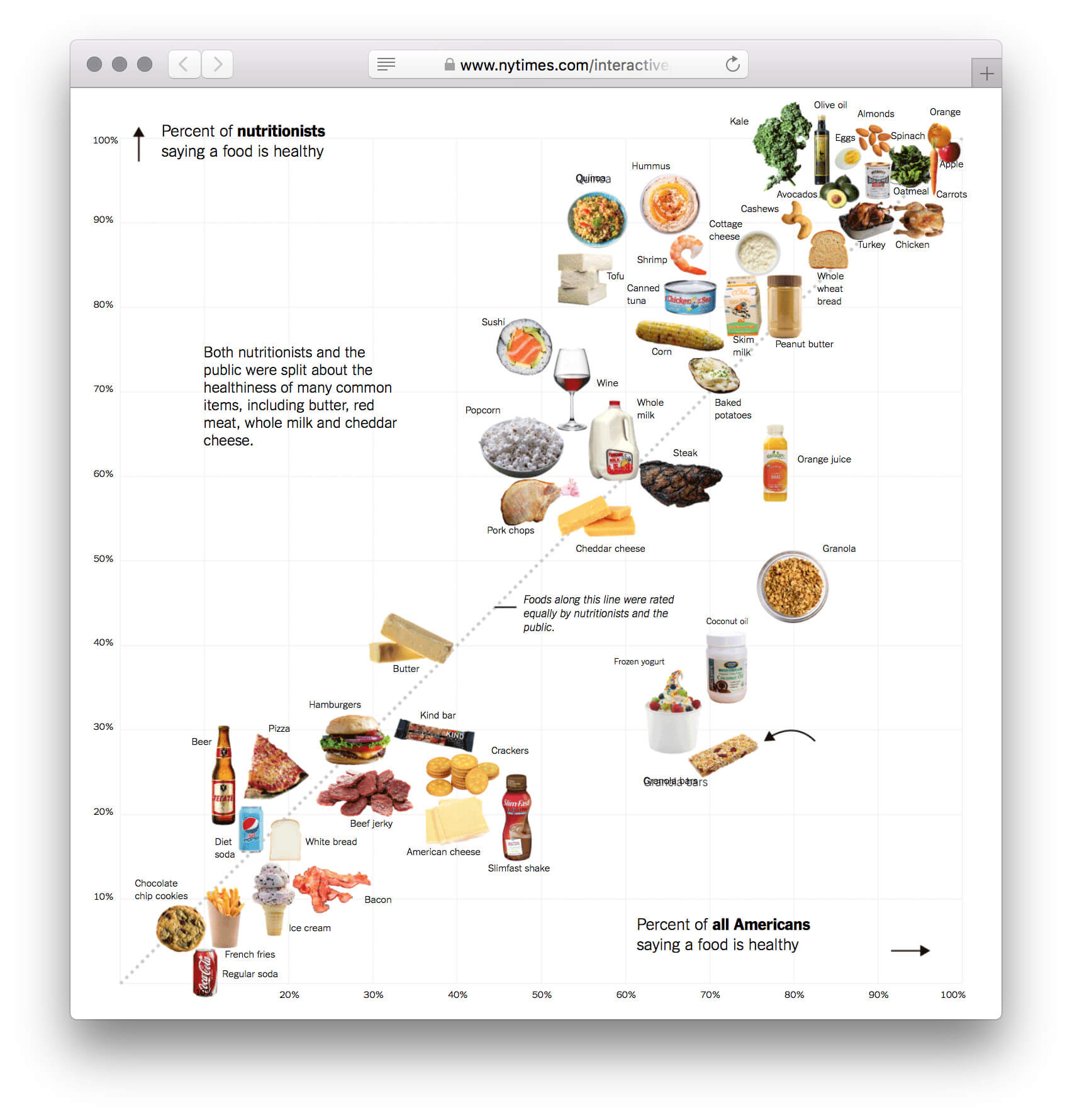
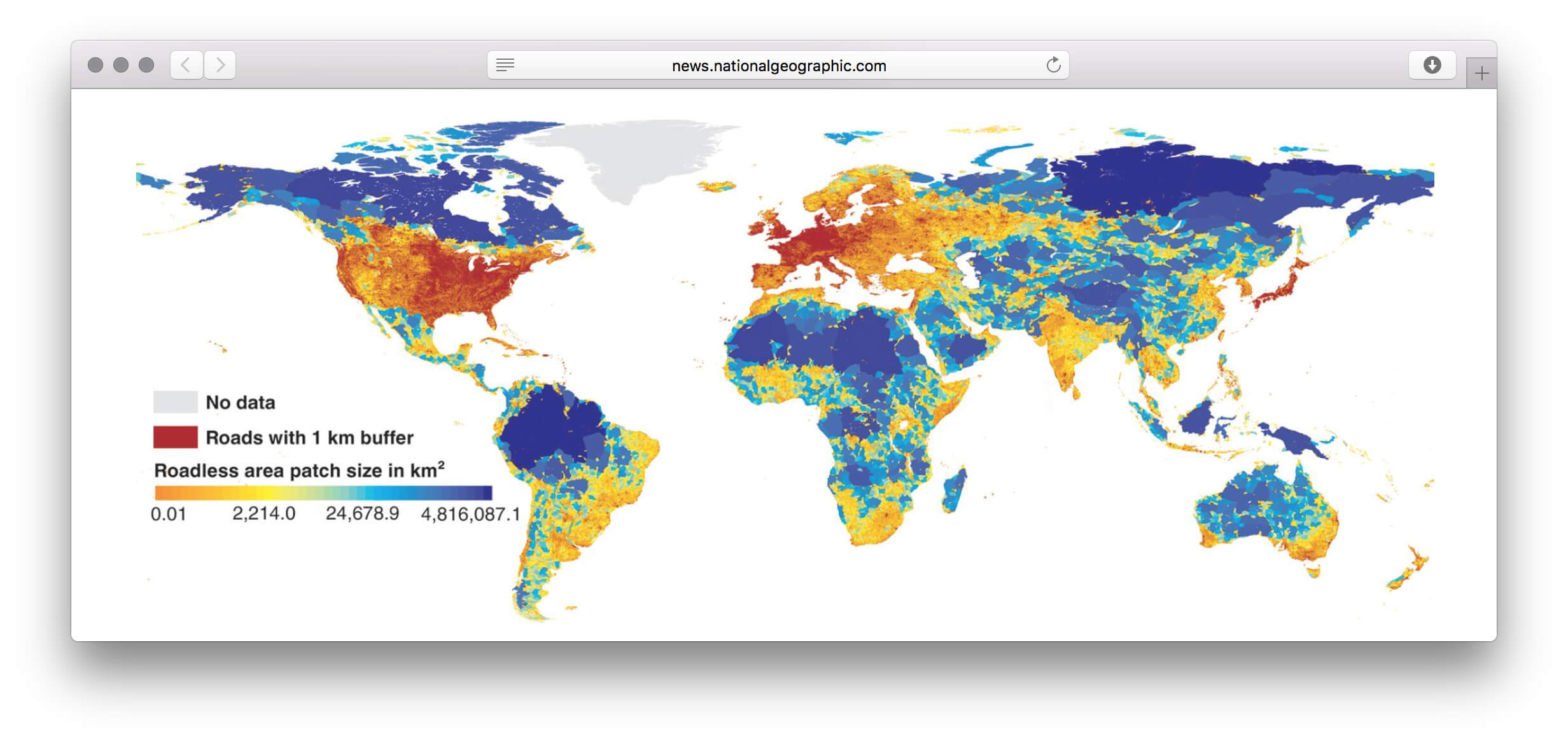
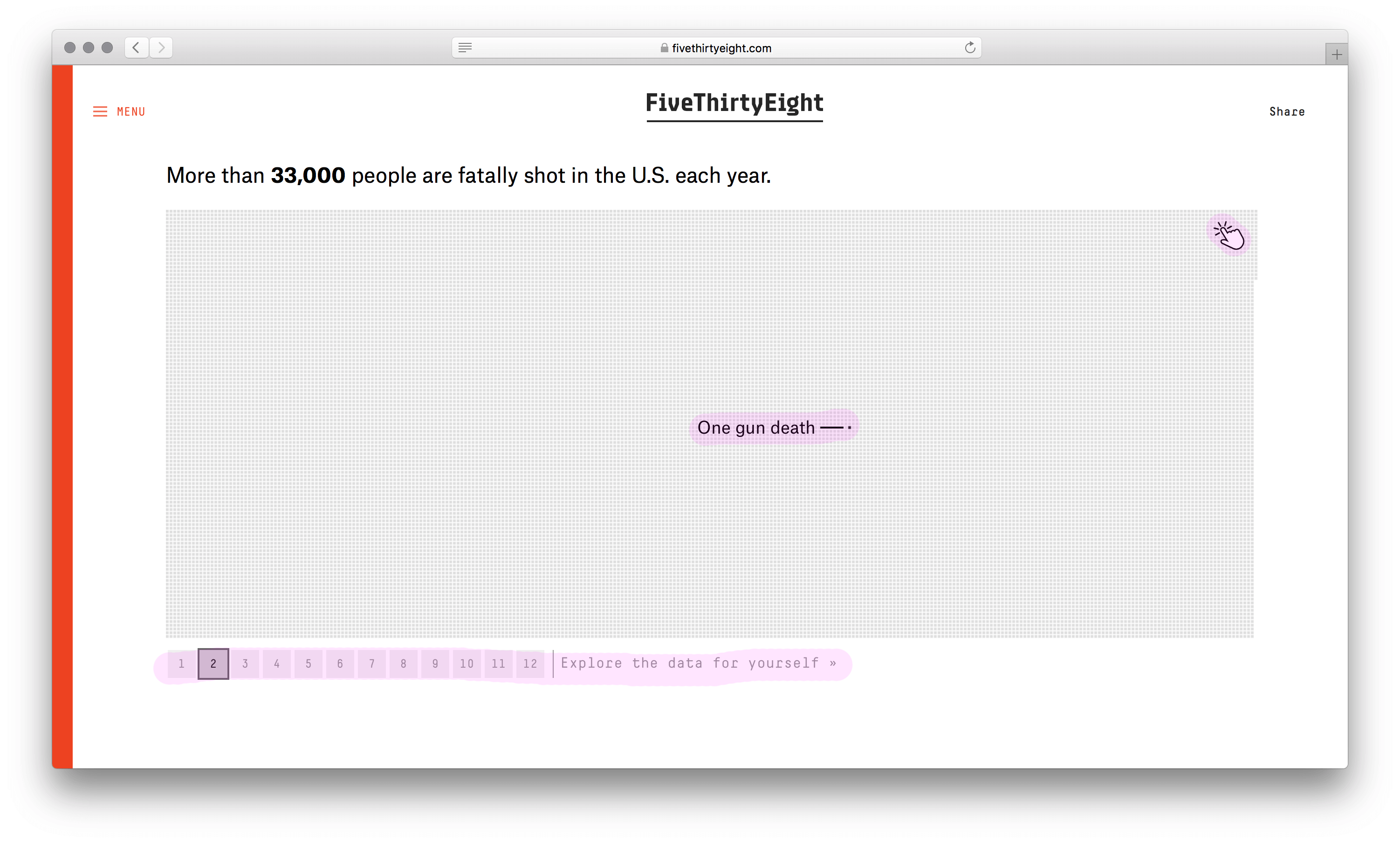
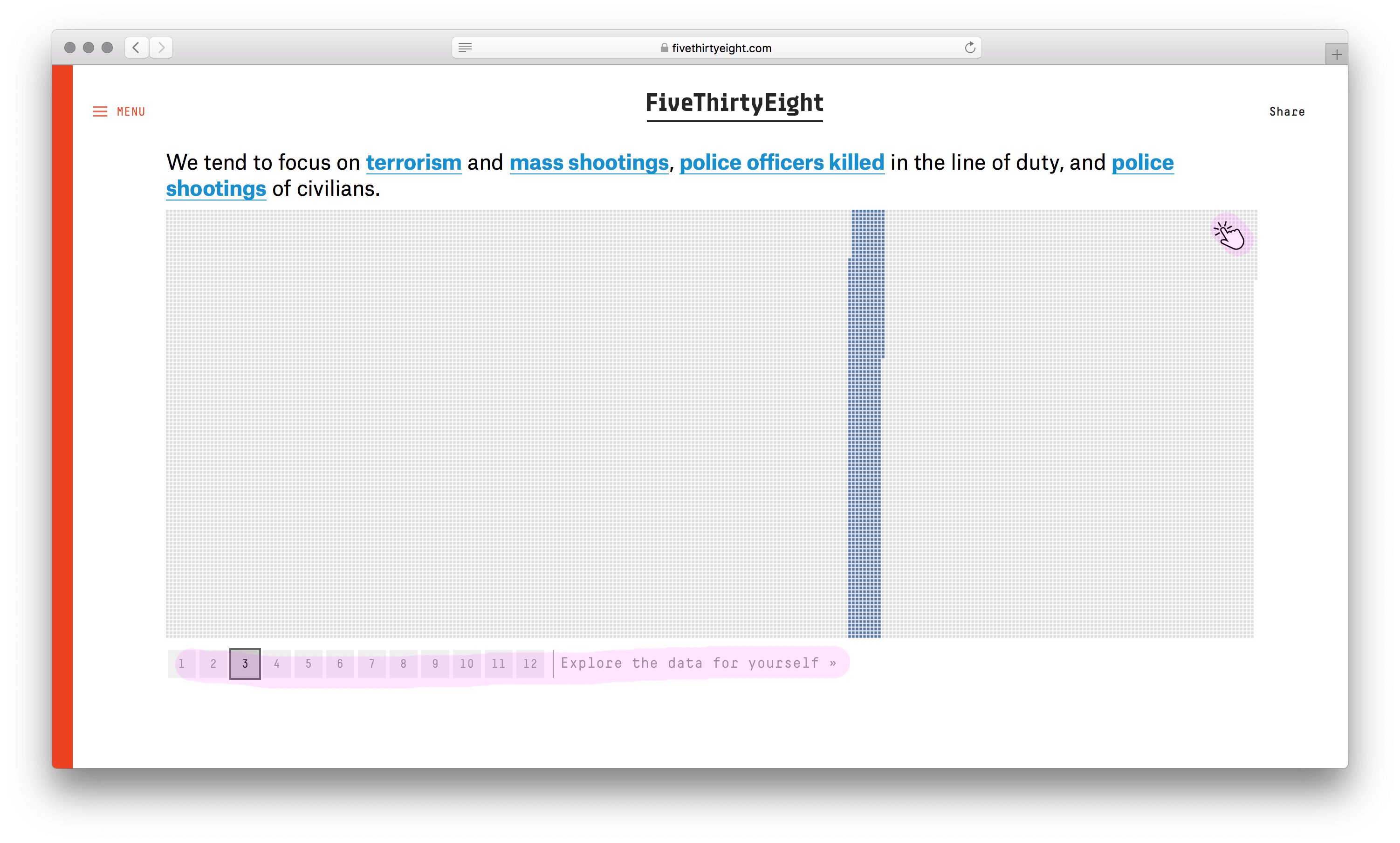
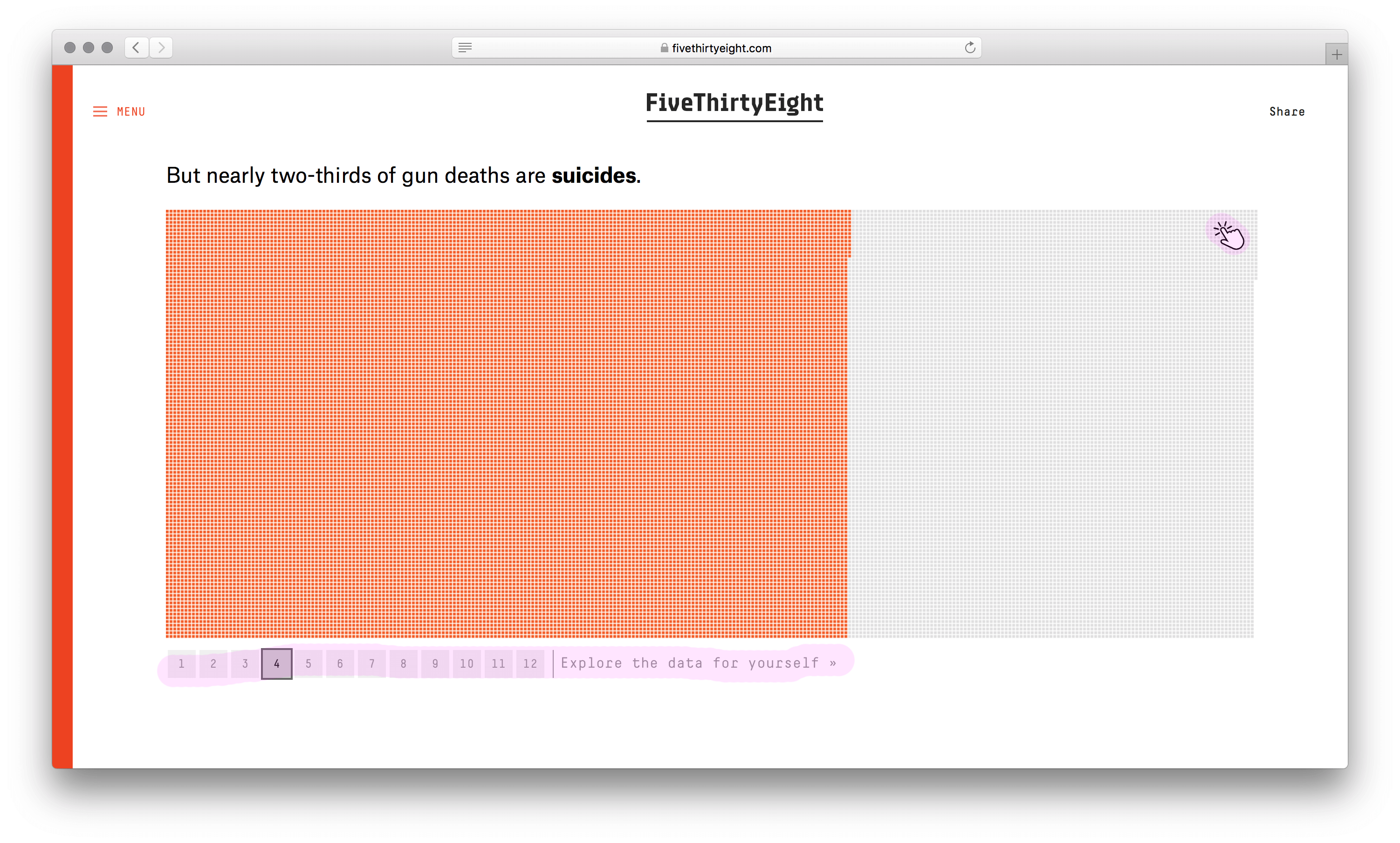
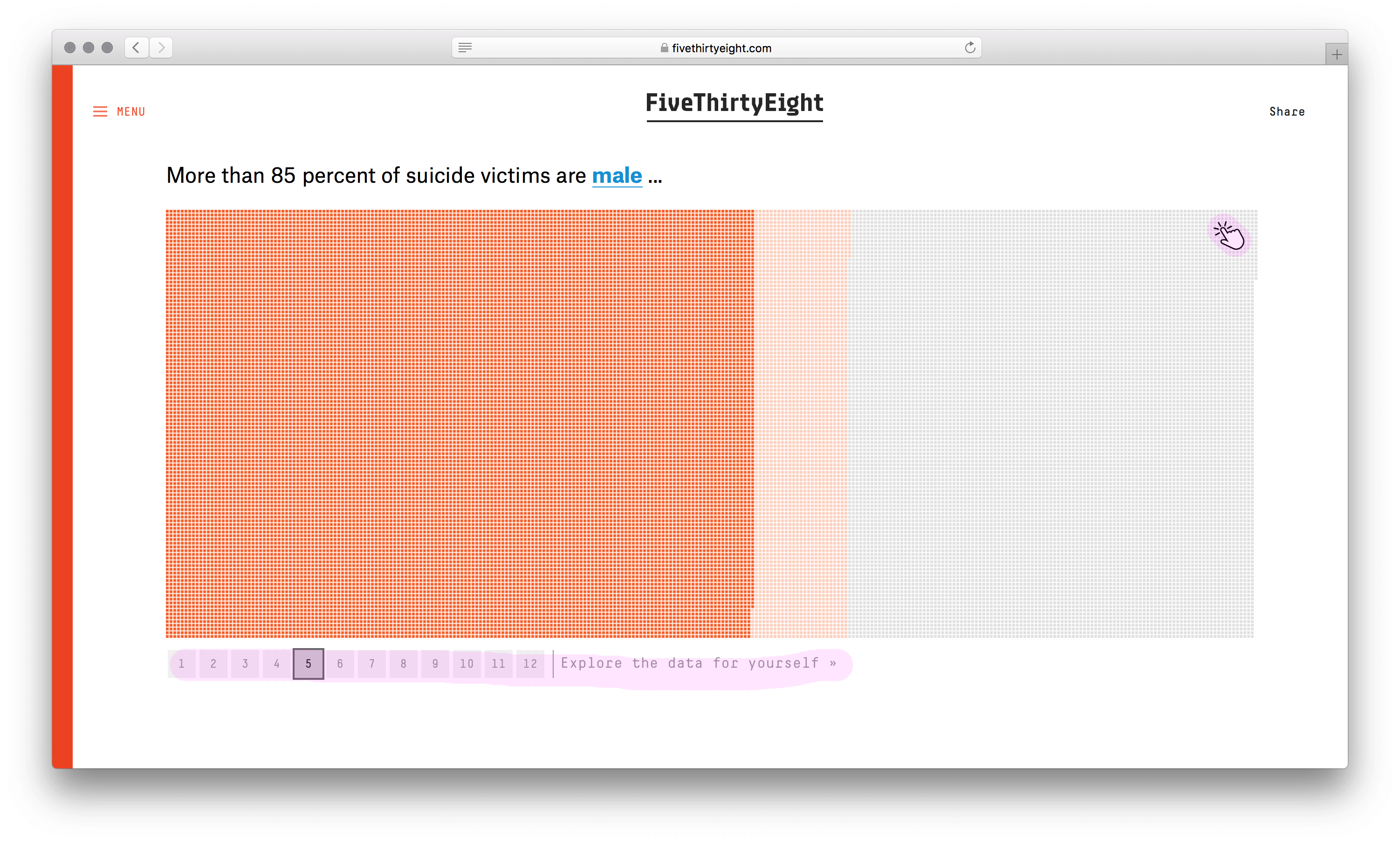
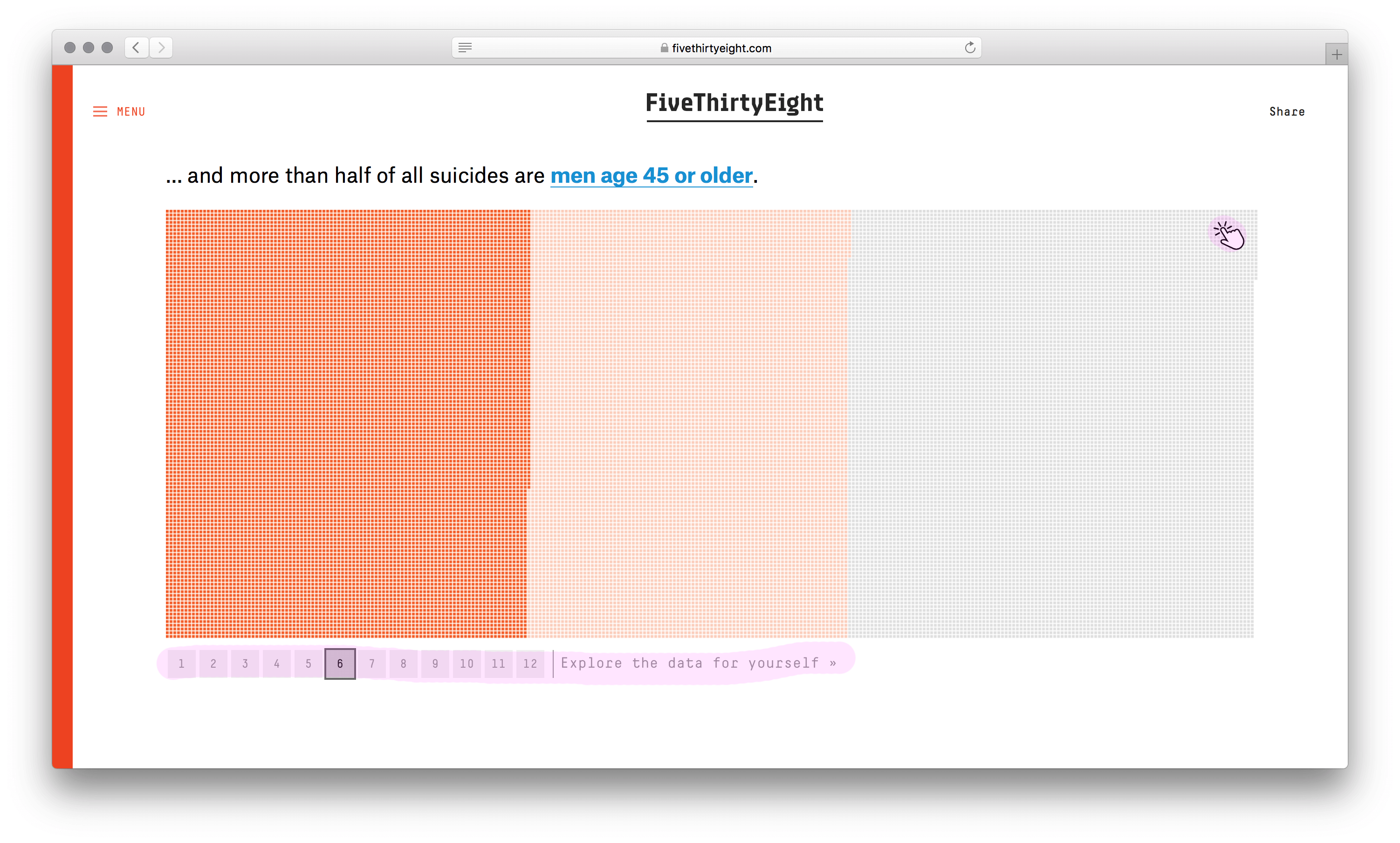
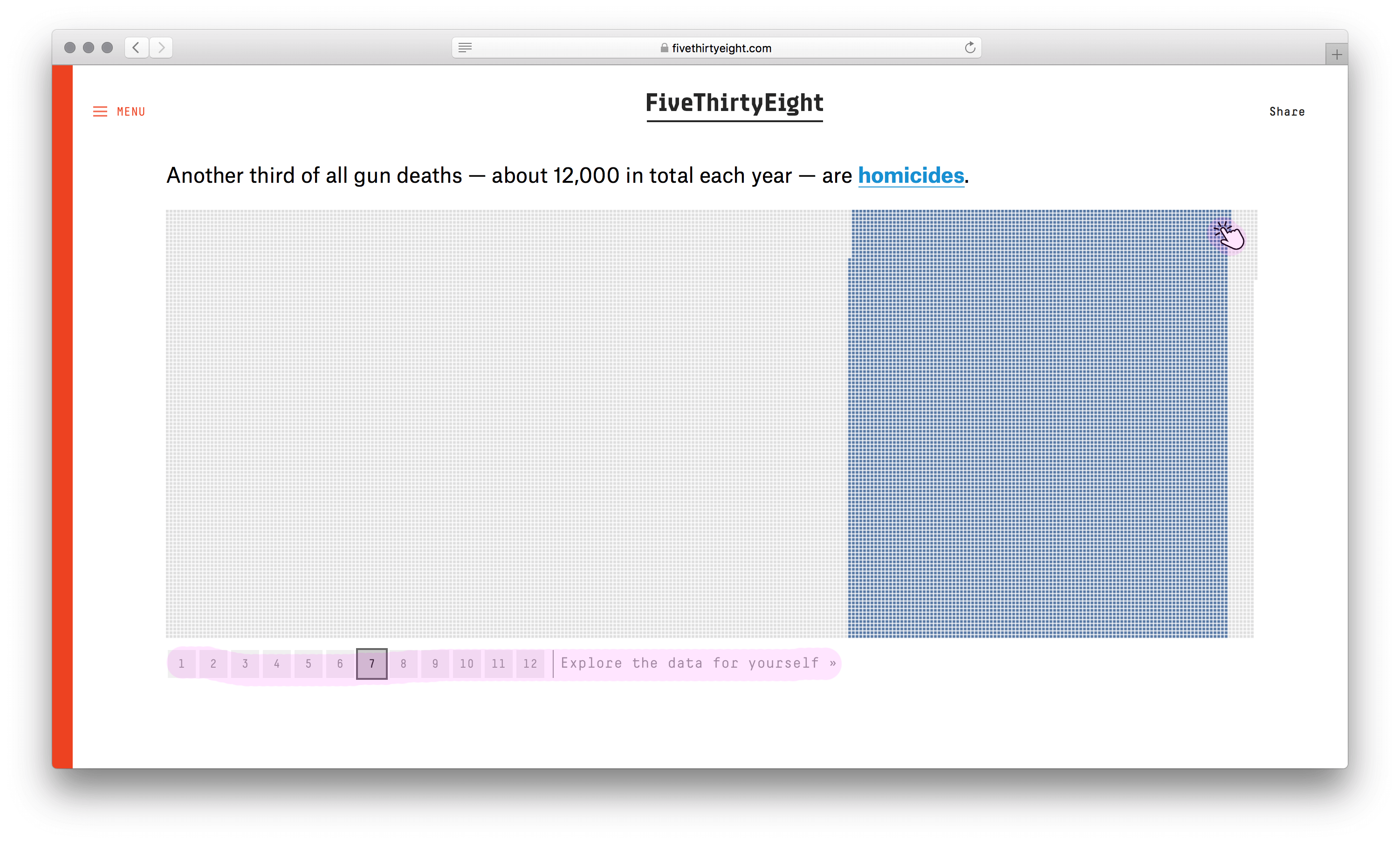
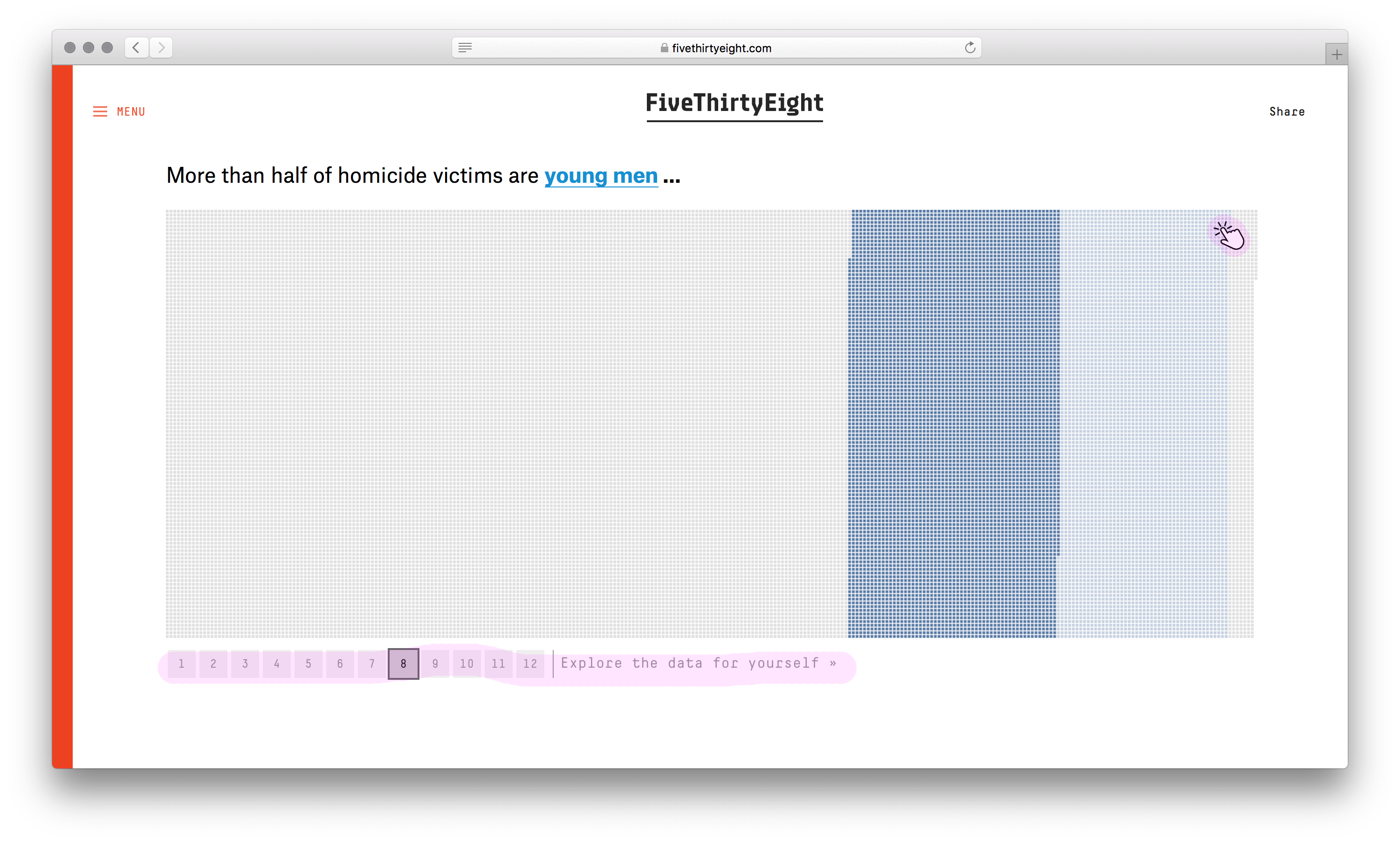
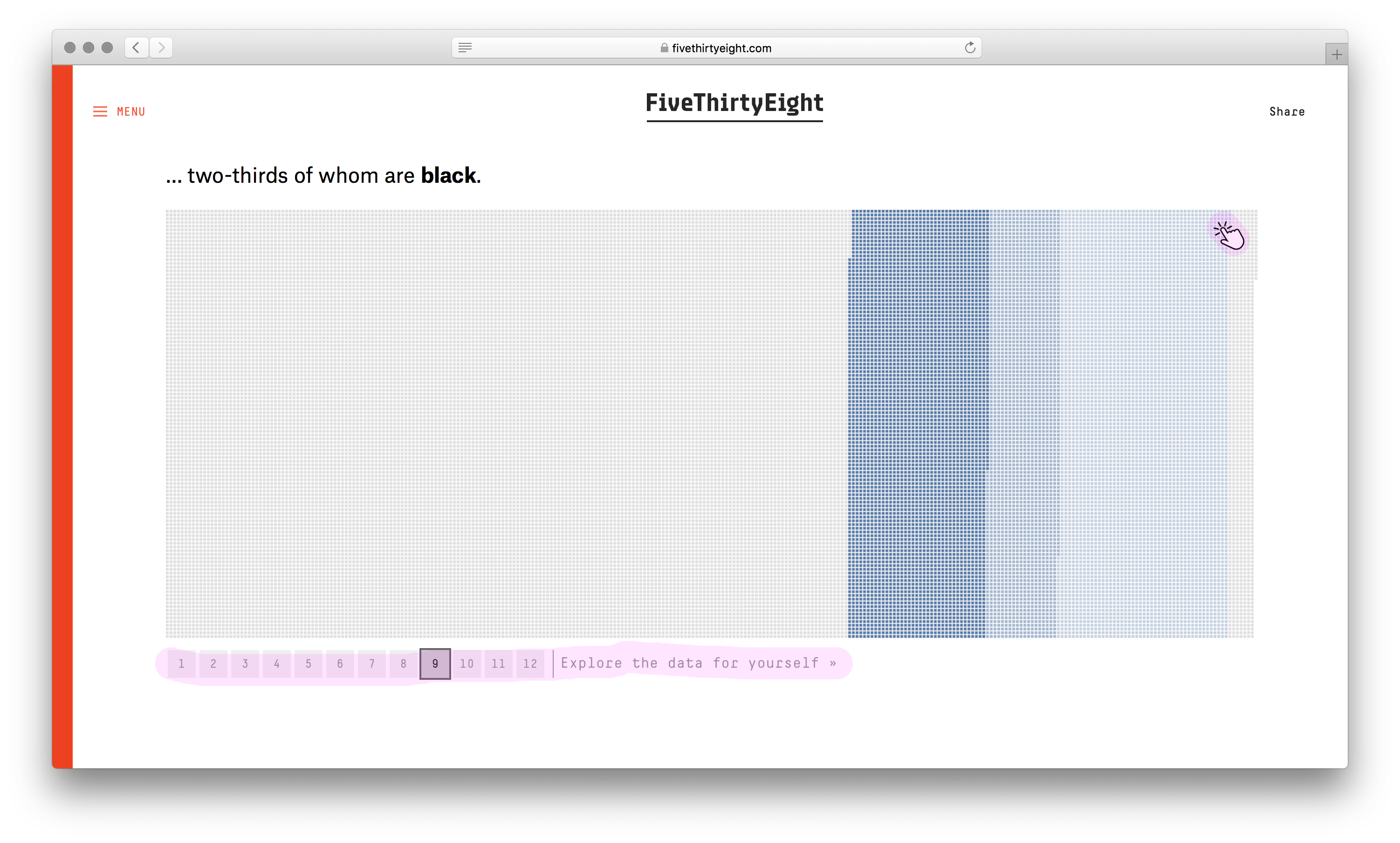
У визуализации сильный каркас. Не столбики с числом погибших мужчин и женщин, не круги рас, не график с возрастом, а наглядное полотно погибших. Данные без агрегации уложили в ряд по вертикали. Второе измерение (горизонталь) понадобилось из-за ограниченного разрешения глаз. Один столбик столько точек не воспринять. Этим ограничением формат похож на текстовый блок с текучими буквами и словами.
Хорошо выбран минимальный элемент — одна человеческая жизнь. Причины смерти, возраст, пол и раса кодируются цветом. Одна за другой потерянные жизни заполняют полотно, собираясь в группы. В лаборатории этот элемент называют элементарной частицей данных. Похожую частицу взяли авторы видеовизуализации о погибших во Второй мировой. Они оперируют не одной смертью, а тысячью.
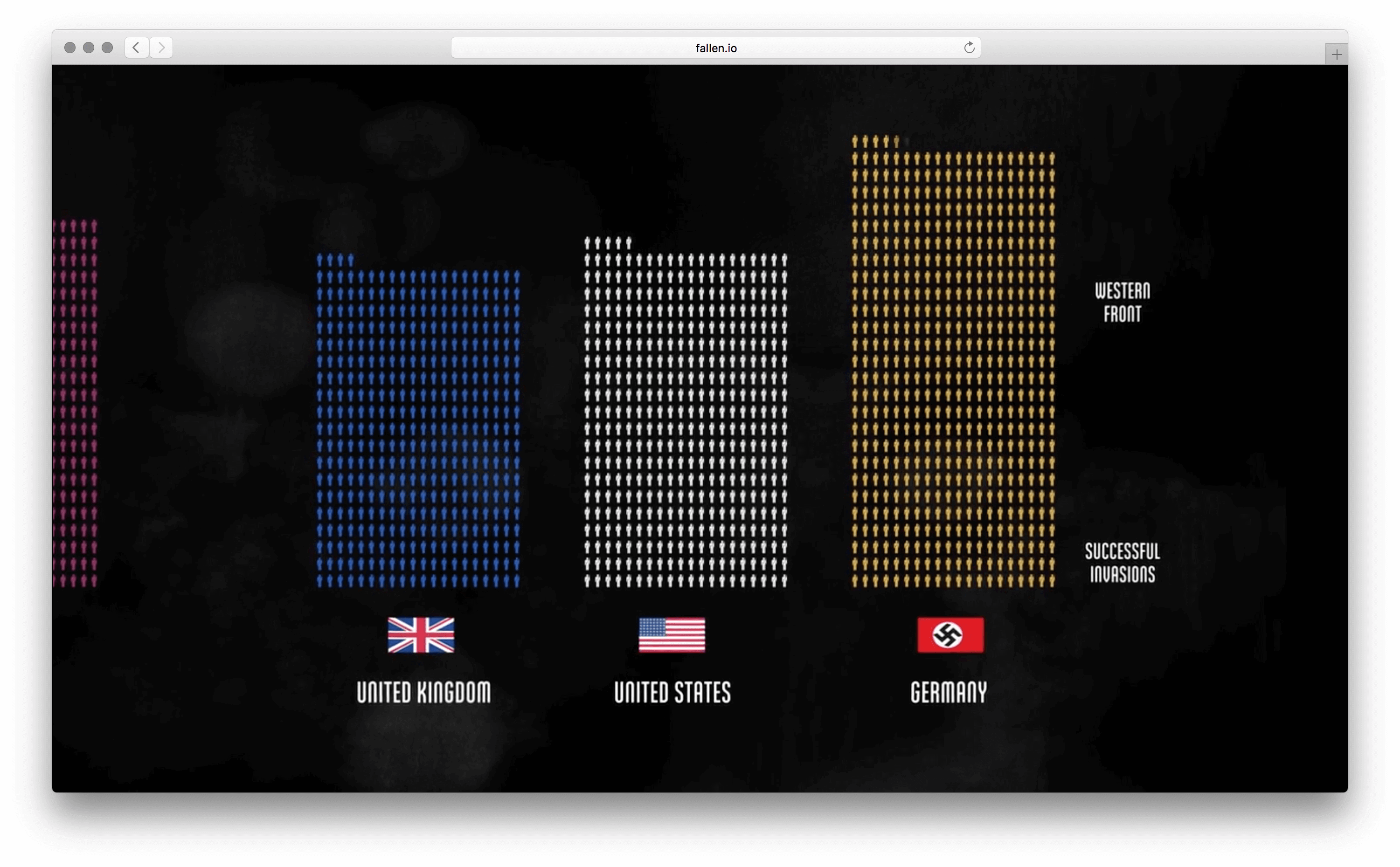
В этих работах отличается визуальное кодирование частиц (визуальный атом). Во 2-й работе атом выбран нагляднее — пиктограмма человека. Такое кодирование помогает обойтись без пояснений. Плюс привлекает больше внимания, чем безликие квадратики.
«Смертность от огнестрельного оружия» получила золотую медаль крупнейшего международного конкурса инфографики «Малофей». По-моему, оценка завышена.
Визуализация разбита на 12 шагов. За каждое предложение зритель платит кликом и распознанием обучающих элементов. Я выделил не относящиеся к делу элементы.
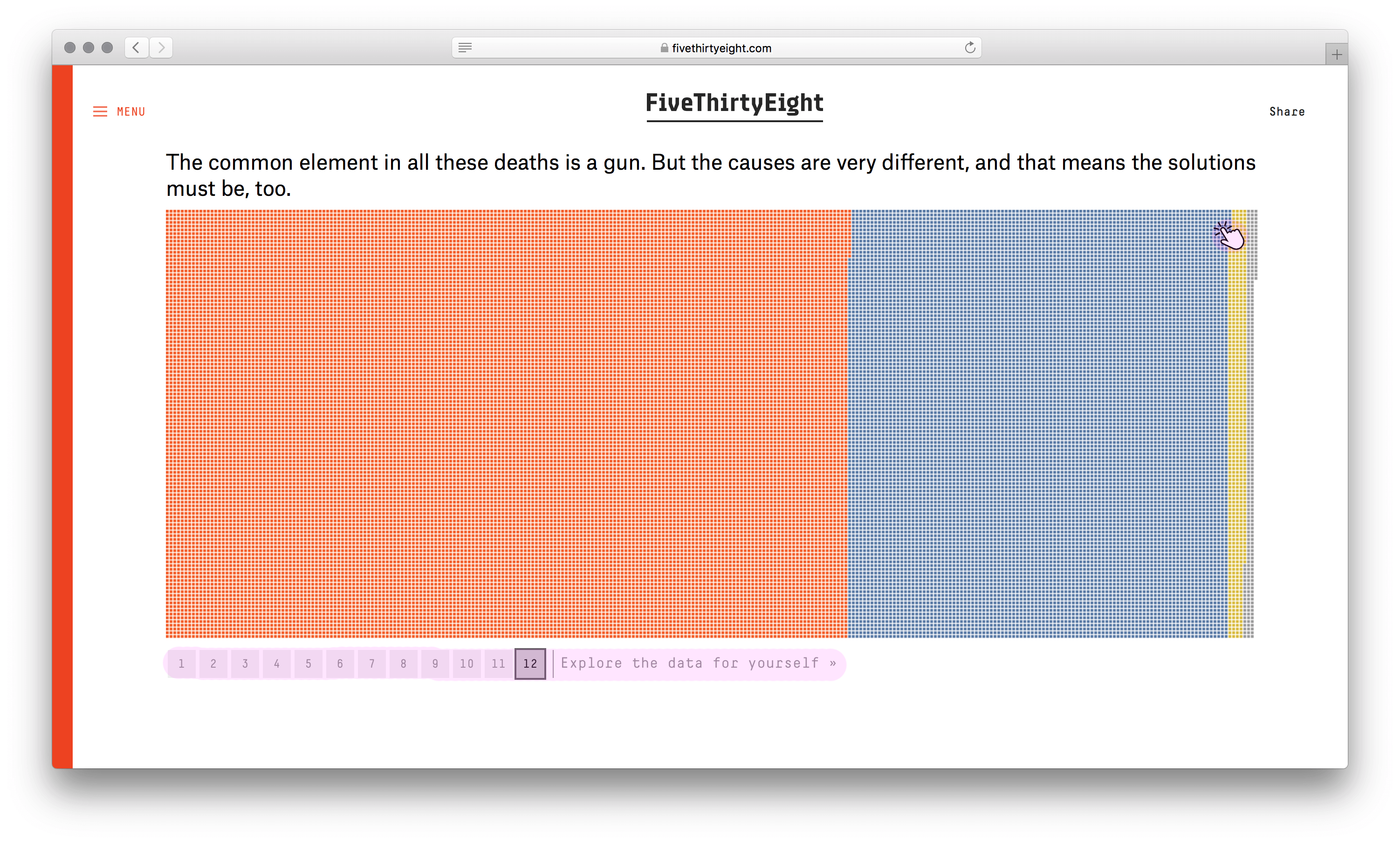
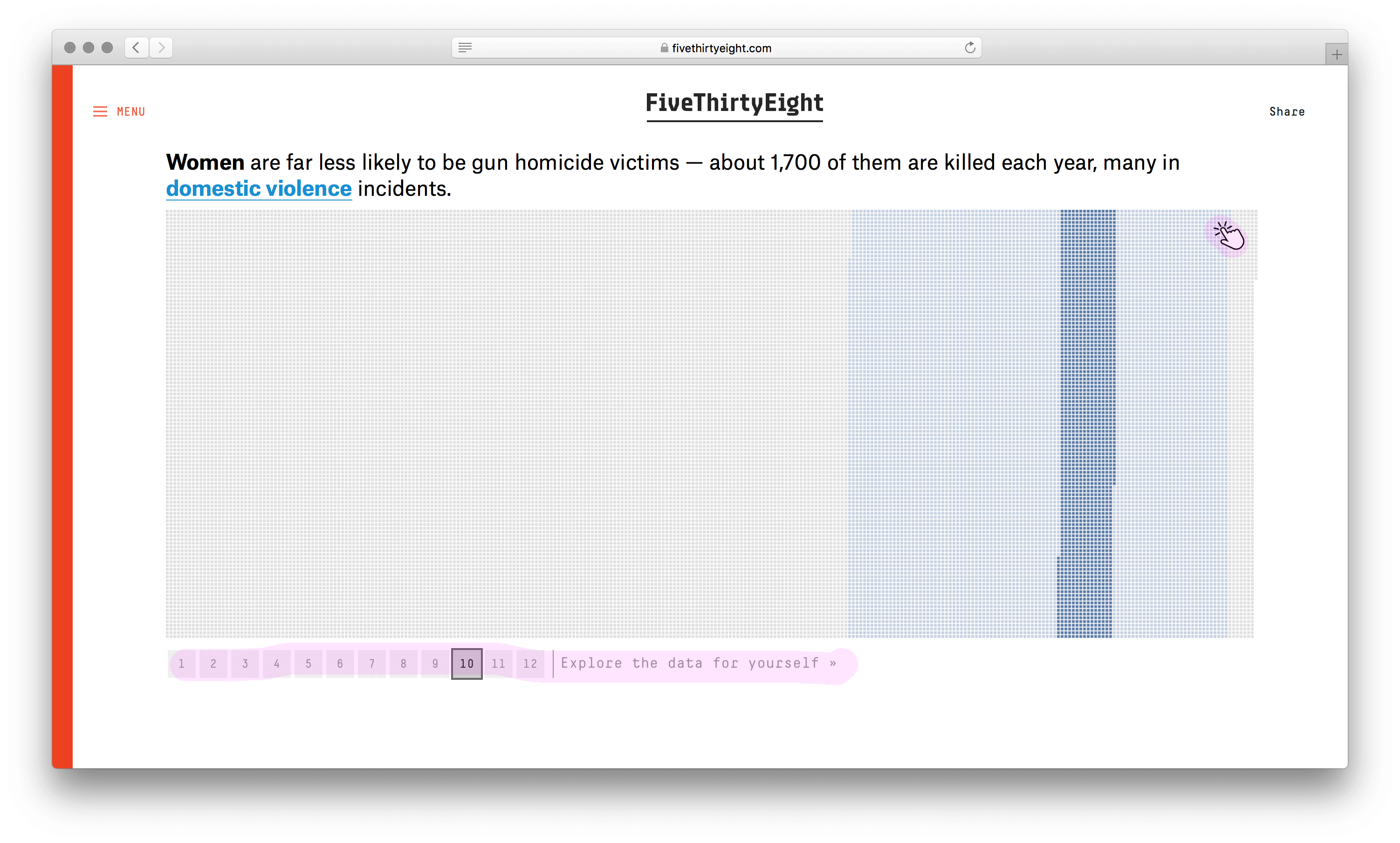
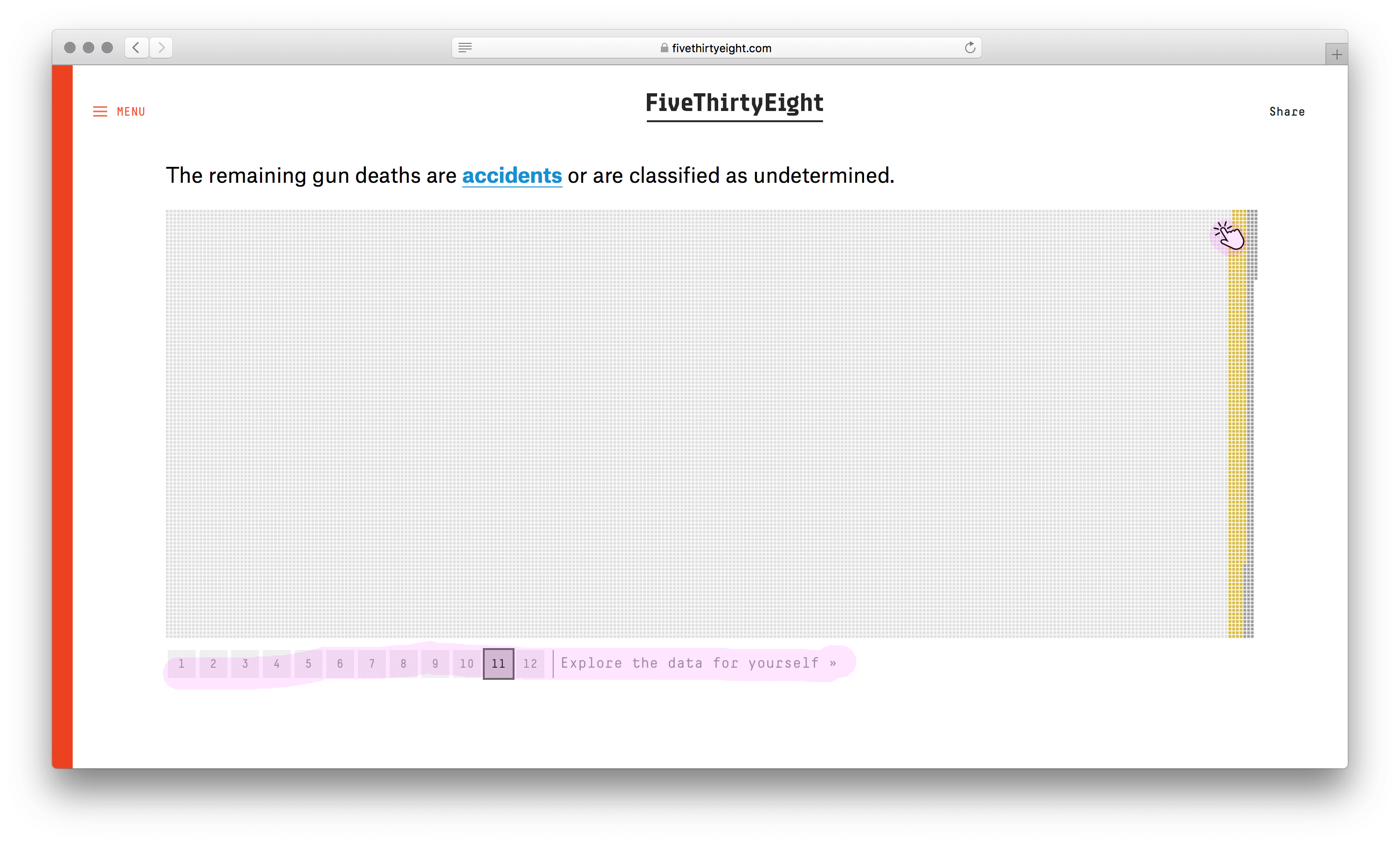
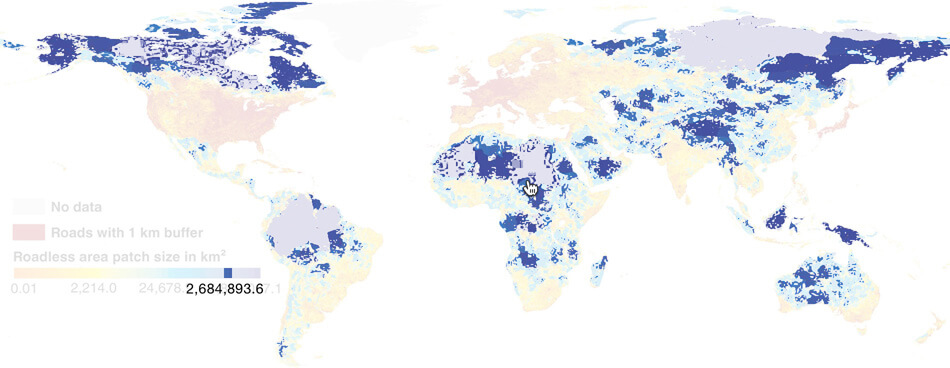
Есть режим с фильтрами. Но в нём погибшие теряют исходные цвета и расположение, что затрудняет сравнение.
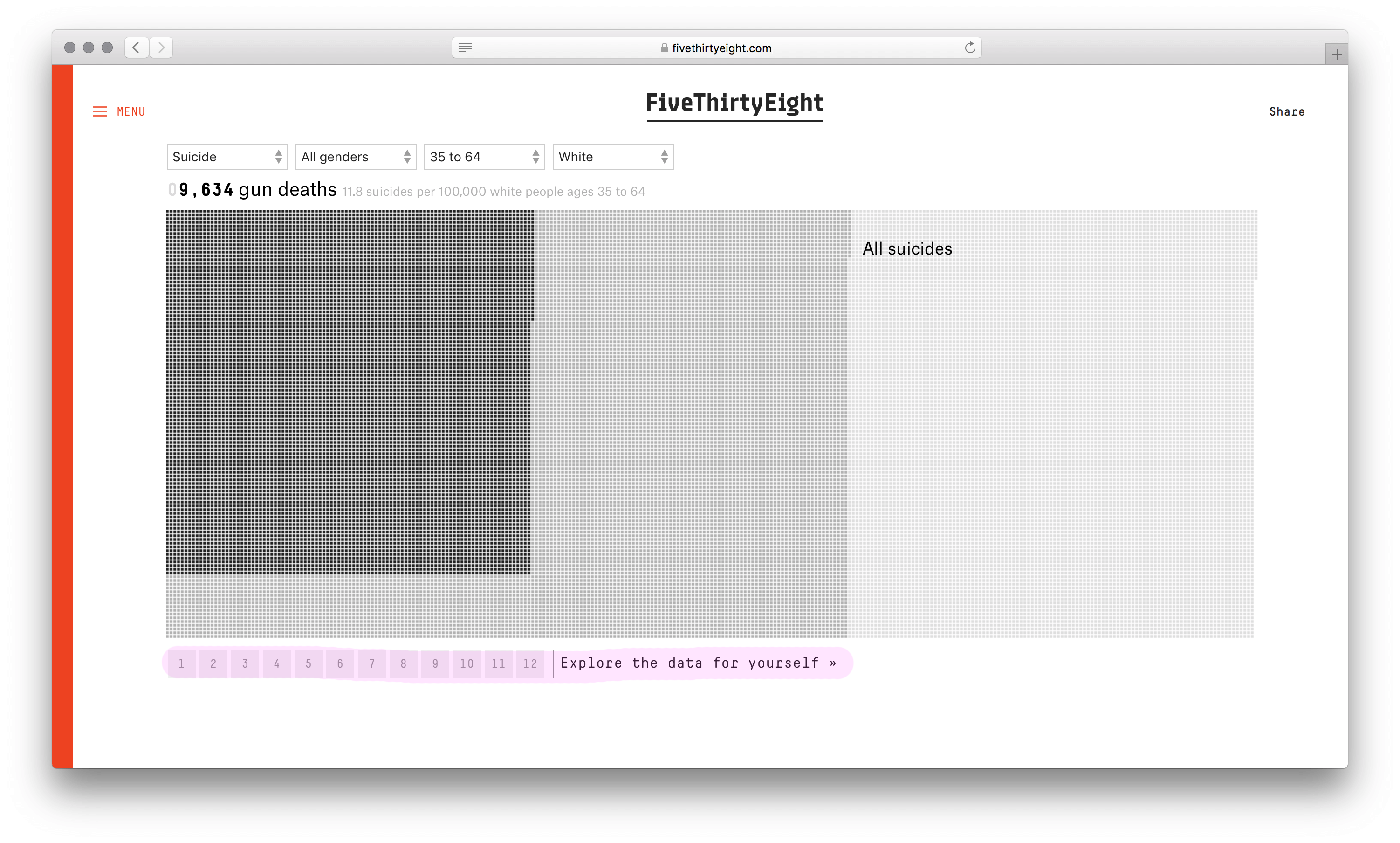
Моя версия — вариация на тему, потому что я не знаю задачи авторов. Свою сформулировал так: «как сделать сравнение выборок интересным и увлечь больше зрителей?»
Сначала я меняю визуальный атом с квадратика на сердечко — оно символизирует потерянную жизнь. Показываю все данные сразу. Обучение и шаги больше не нужны.
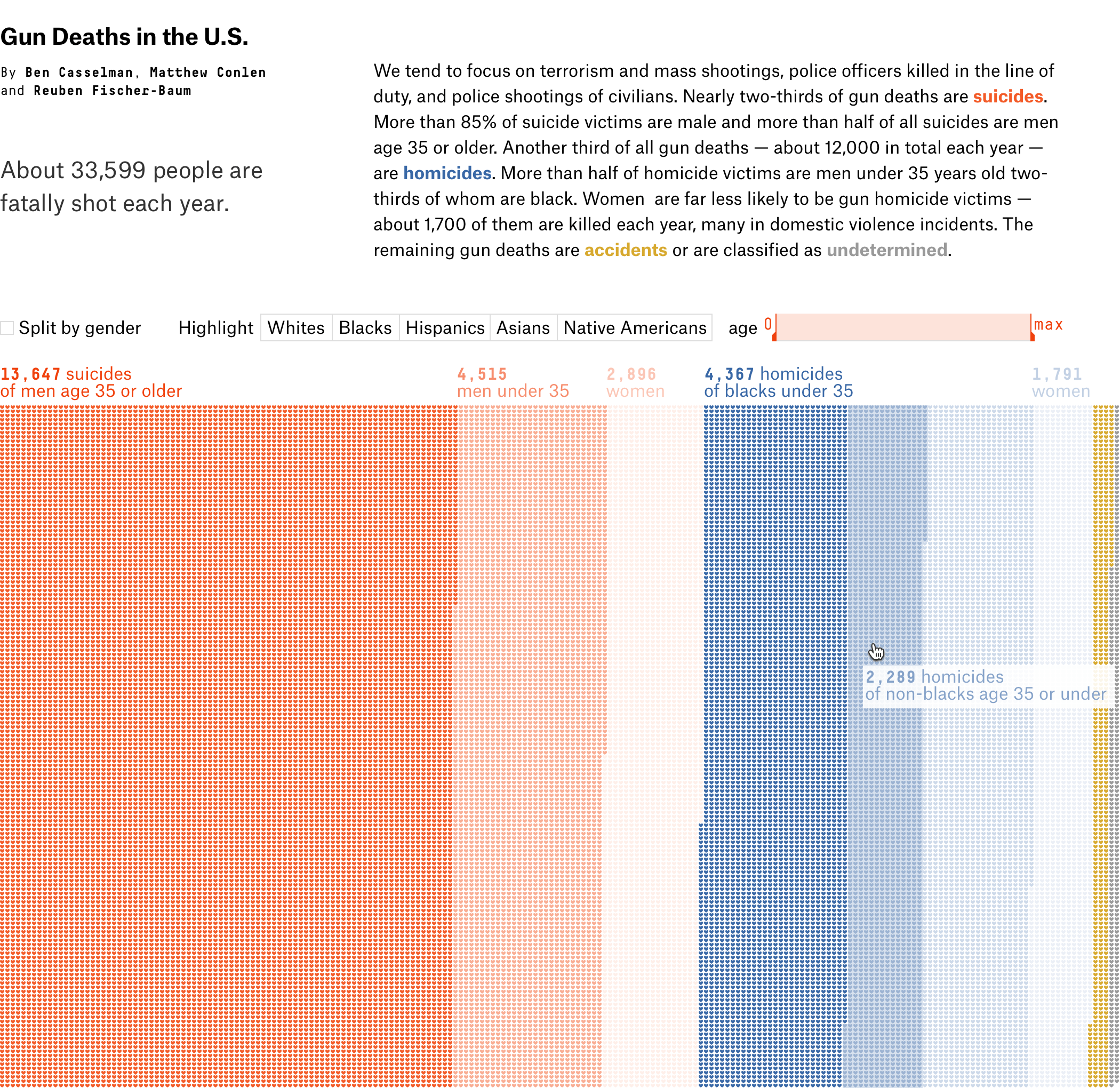
Потом меняю работу фильтров так, чтобы всегда было видно причины смерти в выборке и состав оставшейся части. Использую силу каркаса: как не настраивай выборки, число погибших останется, поменяются только цвета. Так почему бы не покрасить точки антивыборки, повысив информативность? Например, 1) разделили по полу, 2) потом выбрали «белых» старше 35 лет, 3) убрали деление по полу:
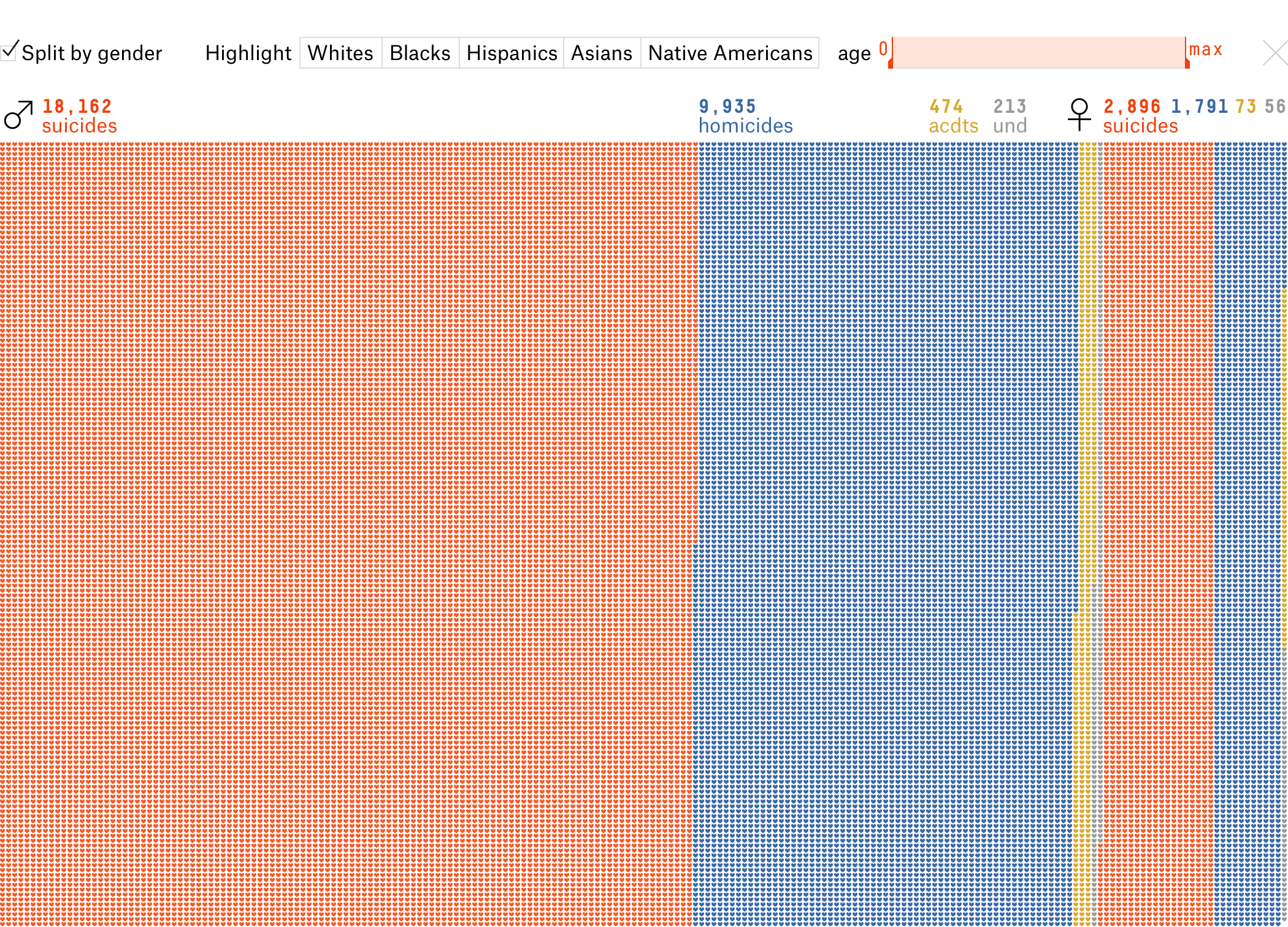
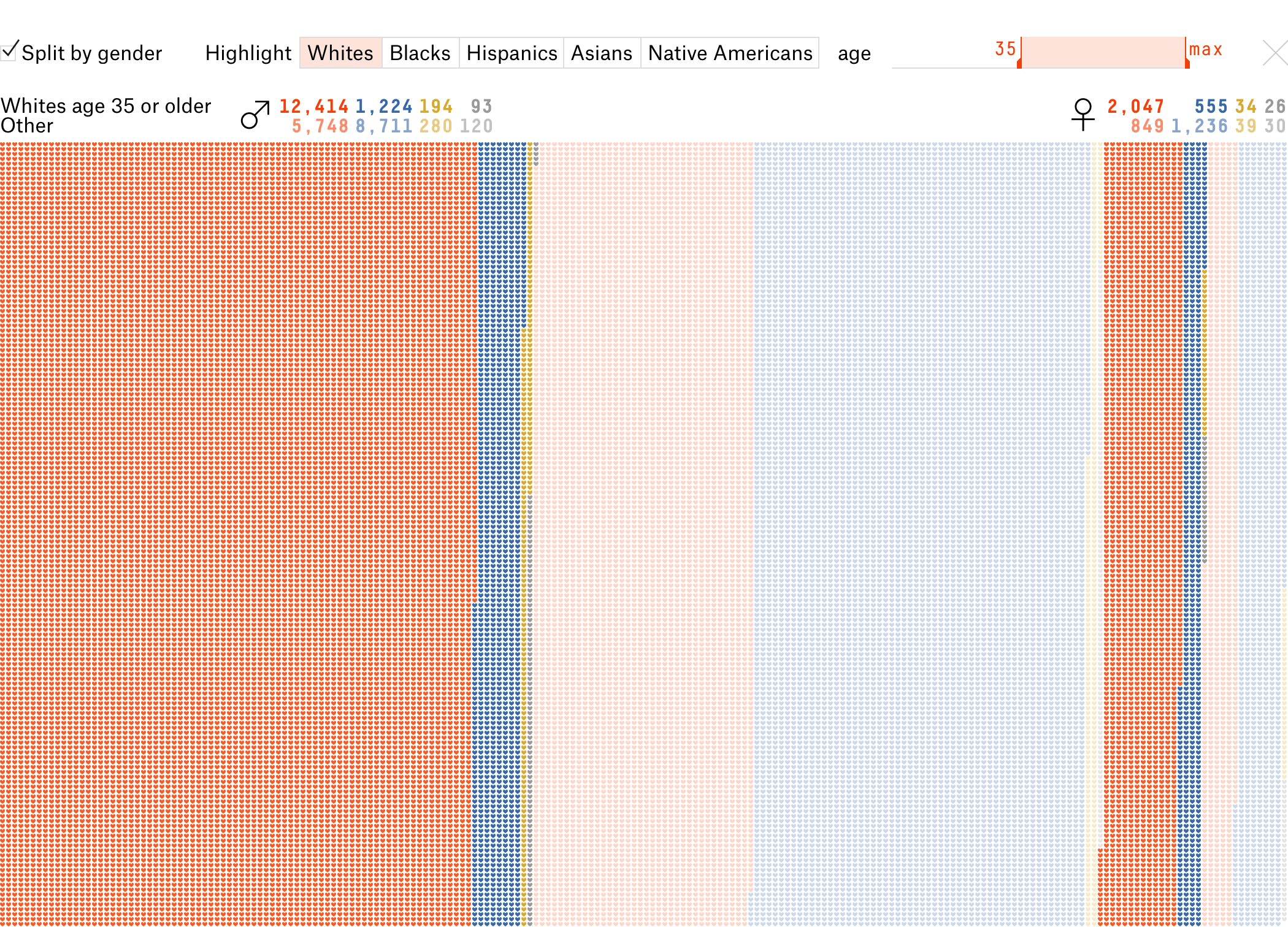
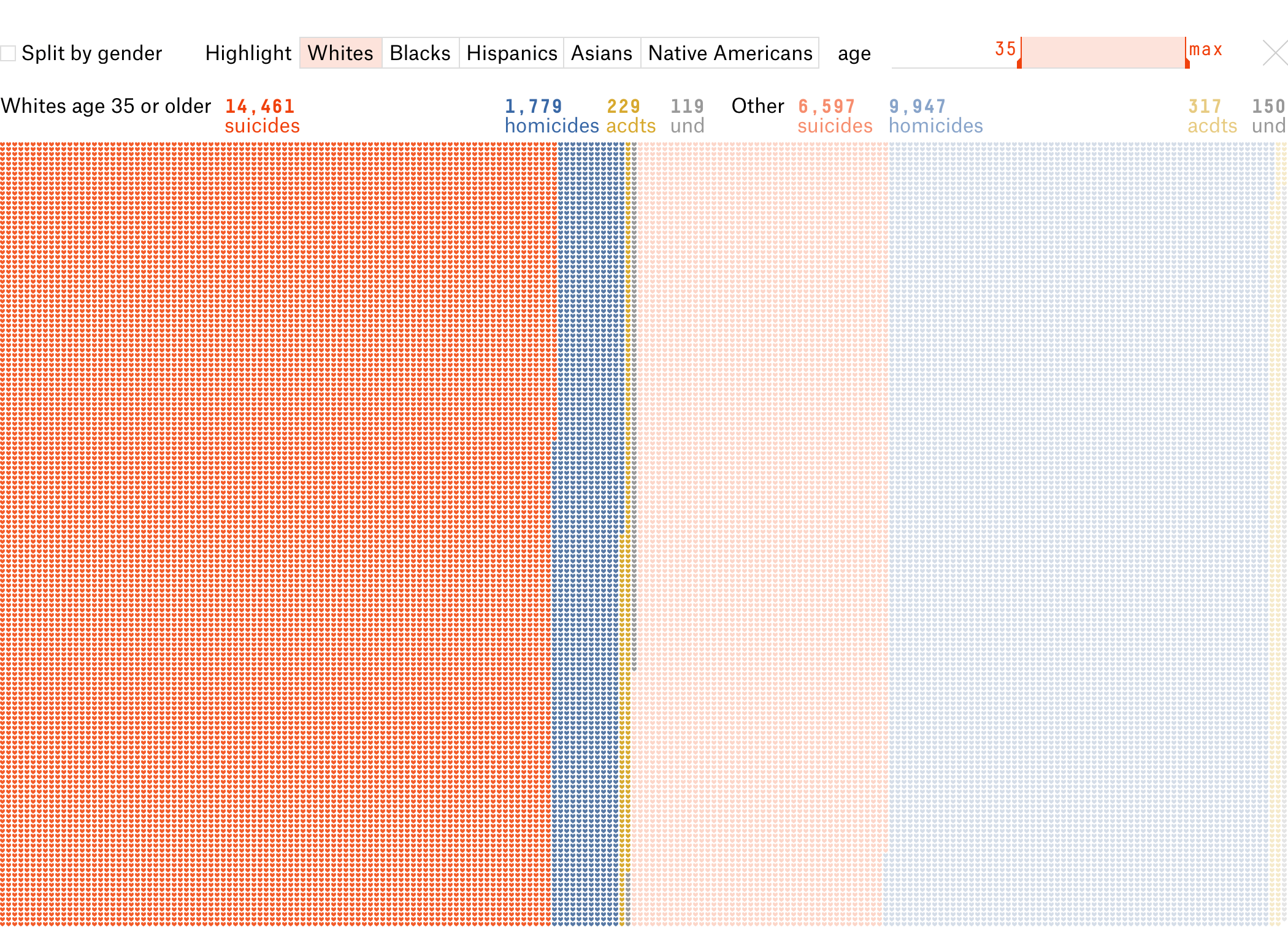
Получается, один жест настаивает несколько выборок, которые интереснее сравнивать.
Следующий разбор — в июле. Ещё хотел позвать на курс «Визуализация данных», который начнётся в субботу, но оказалось, что мест уже нет.